# 高性能网关
**Repository Path**: manong99898/self-developed-api-gateway
## Basic Information
- **Project Name**: 高性能网关
- **Description**: 核心功能:
基于Netty基础实现简易网关,为打造企业级高性能网关奠定基础,掌握Netty网络编程以及API网关核心功能开发
引入Nacos作为注册中心以及配置中心,提供可扩展的接口,掌握抽象接口设计能力以及对Nacos的深度应用能力
网关完善,包括过滤器、熔断降级限流、指标监控、日志功能、鉴权,穿插设计模式、可插拔式的
思想,掌握各种生产级功能的设计开发能力
- **Primary Language**: Java
- **License**: Not specified
- **Default Branch**: master
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 9
- **Created**: 2024-01-19
- **Last Updated**: 2024-01-19
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
# 自研高性能网关项目的开发文档
# 为什么会出现Gateway这个项目?
成熟的框架开发的好处在于其支持快速整合和部署,并且由于其经过了长时间的市场检验,稳定性也能得到一定的保证。但是虽然人家开放了源码给你阅读,但是遇到问题的时候也就意味着你只能花时间从头去了解和排查问题,这就在一定程度上增加了我使用它的成本,他虽然表面看上去是一个透明的箱子,但是在我使用他的时候,只要遇到了问题,我依旧需要将我的手伸进去去触及那些我未曾了解的细节。并且,成熟稳定可能也就意味着考虑过多,过多的将一些当前项目所不需要的功能整合进系统,导致系统过度冗余,那么此时,我们肯定是希望能基于自己的需求开发出一个适应自己需求的网关的。因此Gateway也就应运而生了。
# 为什么需要自研网关?
其实我认为思考问题一个很好的方式是从反方向去思考,我可以先列举出直接使用成熟框架的好处,那么它的好处的反方向就是他的缺点。也就是设计自研网关的必要性。所以我当初思考了几个开源框架的好处,然后从侧面思考,就能思考出其缺点。
1. **稳定性**:
- **优点**: 稳定性意味着可靠的行为和预期的输出。
- **缺点**: 过度的稳定性可能导致在特定场景下缺乏灵活性,使得实现特定功能变得复杂或效率降低。
2. **社区支持**:
- **优点**: 丰富的社区资源和文档。
- **缺点**: 过度依赖社区支持可能会在需要快速解决或定制问题时,受限于社区的响应速度和可用的专业知识。
3. **快速开发**:
- **优点**: 现成的功能和简单的配置可以加速开发。
- **缺点**: 为了通用性而设计的功能可能不适合所有的用例,可能会导致性能不是最优化的,或者需要做额外的工作来适配特定需求。
4. **集成能力**:
- **优点**: 与广泛的其他服务和组件有良好的集成。
- **缺点**: 这种集成可能会限制新技术的采用,因为新技术可能不兼容或未经优化。
5. **成本效益**:
- **优点**: 可以节约初期的资源投入。
- **缺点**: 随着时间推移,可能需要投入更多的资源去学习、调整和扩展开源网关以满足特定需求,这可能会抵消初期的节省。
从简单且更加片面的角度去看,自研网关的好处有如下几点:
1. **完全控制**: 自研网关意味着拥有对网关功能的全面控制,团队可以根据具体业务需求定制网关行为,不受外部项目的限制。这包括路由决策、安全性检查、流量控制和日志记录等。
2. **定制的性能优化**: 可以针对特定的用例和环境进行性能调优。例如,如果某个服务需要非常高的吞吐量或极低的延迟,团队可以优化代码和配置来满足这些特定的性能要求。
3. **特色功能**: 在内部网关中实现独特的业务逻辑和集成,例如,自定义认证/授权机制,特殊的转换逻辑,或者与内部系统的特殊集成。
4. **减少依赖**: 自研网关减少了对外部开源项目维护速度和方向的依赖,这在某些情况下可能避免了被迫跟随外部变化带来的风险。
从更加高维的视角去看,为什么需要一个自研网关?
1. **成本考虑**: 成熟的网关产品在未来可能会引入不兼容的更改或弃用特定特性,导致企业不得不进行昂贵的迁移或重构。自研网关则完全控制版本和功能迭代,避免了这种风险。
2. **技术因素**: 对于使用非HTTP协议(如TCP、UDP直连或专有协议等)的老旧系统,市面上的网关产品往往只提供有限或无支持。自研网关可以确保与这些系统的兼容性,证据在于许多遗留系统的成功集成案例,例如金融行业中特有的交易协议。
3. **网络和安全性能**: 在对网络延迟极为敏感的交易系统中,即使是毫秒级的改进也具有重大意义。自研网关可以针对特定的网络环境和数据流模式进行优化,有的金融机构通过内部开发的网关减少了30%的网络延迟。
4. **组织和运营**: 自研网关的更新和迭代可以与企业的CI/CD流程紧密集成,这为企业带来了更高的敏捷性和响应市场变化的能力。在许多成功案例中,企业能够在几小时内部署网关更新以支持新的市场需求或应对安全威胁,而不是等待第三方发布更新。
5. **市场和竞争优势**: 通过自研网关提供的独特服务或功能,企业可以在市场上建立独特的卖点。例如,Amazon的API Gateway提供了与AWS服务的深度集成,这是它们的一个关键竞争优势。
6. **创新驱动**: 自研网关允许企业实现最新的技术研究成果,而无需等待这些功能在开源项目中可用。例如,谷歌的ESPv2 API网关就是在开源的Envoy基础上,集成了谷歌特有的安全、监控和控制策略。
其实,上面说的都太高大上了,从个人角度的层面来说的话,一个自研网关的作用难道不是,在自研项目的过程中,增加你对架构设计,语言特性以及你的知识面嘛。
同时,一个好的项目也意味着给你的简历,给你的经历添上浓墨重彩的一笔。
我也靠着这个项目拿到了一些大厂的offer(this is the real intention)
# 了解他人,认识自己
所谓知己知彼百战不殆(哈哈哈我想这个地方不应该用这句话)。
我的意思是,在你设计一个项目之前你肯定需要去分析设计这个项目在市场上的已经存在的项目中,和他们去做区分,了解各个项目的优缺点,然后提炼出你自己设计这个项目的一个设计方向。
所以我调查了市面上已有的且比较知名的网关项目,列举出了如下这张优缺点表格。
| **Gateway名称** | **优点** | **缺点** | **设计侧重点** |
| --- | --- | --- | --- |
| **Nginx** | **高性能,配置灵活,轻量级,高稳定性** | **模块化程度低,扩展性差,异步处理能力受限** | **高性能HTTP服务器和反向代理** |
| **Apache HTTP Server** | **模块丰富,社区活跃,跨平台,文档齐全** | **性能较差,配置复杂,更重量级** | **多功能Web服务器,重视模块化** |
| **HAProxy** | **高性能,支持TCP和HTTP代理,稳定且成熟** | **配置不如Nginx直观,缺乏现代Web界面** | **专注于高并发连接的负载均衡** |
| **Traefik** | **自动化服务发现和配置,容器和微服务友好,易于部署** | **社区较新,历史较短** | **云原生环境中的动态配置** |
| **Kong** | **基于Nginx和OpenResty,提供丰富的插件,管理界面友好** | **高性能场景可能需优化配置,插件生态不如Apache/Nginx** | **扩展性和插件生态系统** |
所以,基于上面这些比较成熟且知名度较高的网关,我也提炼出了我自己设计一个网关的侧重点:
1. **性能与可伸缩性**:
- 关注高吞吐量和低延迟处理,以便能够处理大量并发连接和数据流。
- 设计可在多个服务器、数据中心或地理区域之间伸缩的解决方案。
2. **安全性**:
- 实现高级安全特性,如SSL/TLS终止、OAuth、JWT、API密钥验证和防止DDoS攻击等。
- 确保所有通过网关的流量都符合最新的安全标准和法规要求。
3. **可观测性**:
- 提供详细的监控和日志记录功能,使运维团队能够观测和诊断问题。
- 集成与现有监控工具和警报系统的能力。
4. **路由能力**:
- 开发动态路由和负载均衡策略,以支持微服务架构中服务发现的需求。
- 支持基于URL、路径或头部的路由决策。
5. **扩展性**:
- 构建插件架构,使新功能能够以模块化的方式添加。
- 保持核心轻量级,允许通过插件或服务集成额外功能。
6. **多协议支持**:
- 考虑支持多种网络协议,不仅限于HTTP/HTTPS,也包括WebSocket、RPC等。
7. **高可用性**:
- 确保网关设计能够容忍单点故障和网络分区,提供故障转移和灾难恢复机制。
好的,那么基于上面我列举出来的这些点之后,我就可以开始分析,我应该如何从这些点入手将一个具体的问题拆解为几个细粒度的解决方法,这也是我在字节跳动时我mentor教我的技巧。
接下来我们一点一点的对上面的七个点进行分析,分析其具体的解决方法和思路。
于是就有了如下的答案:
1. **性能与可伸缩性**:
- 使用 **Netty** 进行异步网络编程,Netty 是一个高性能的网络应用程序框架,可以处理大量的并发连接。
- **缓存** 如 Caffeine 或 Redis 来减少数据库访问频率,提升性能。
2. **安全性**:
- 集成 **JWT** 用于安全的API访问。
- 利用 **TLS/SSL** 加密传输数据。
3. **可观测性**:
- 集成 **Micrometer** 或 **Dropwizard Metrics** 来收集和导出性能指标。
- 使用 **ELK Stack**(Elasticsearch, Logstash, Kibana)来收集和分析日志数据。
- 利用 **Prometheus** 和 **Grafana** 进行监控和警报。
4. **路由能力**:
- 利用 **Zuul** 或自定义的 **Servlet Filters** 进行动态路由。
- 结合 **Consul** 或 **Eureka **或** Nacos** 进行服务发现和注册。
5. **扩展性**:
- 设计插件架构,使得可以通过 **Java SPI (Service Provider Interface)** 加载新模块。
6. **多协议支持**:
- **使用 gRPC/Dubbo 来支持RPC调用。**
- 支持 **WebSocket** 用于双向通信,使用Java的 **JSR 356** 或 **Spring Framework** 的WebSocket API。
7. **高可用性:**
- **使用 Nacos / ZooKeeper / etcd 来管理网关的配置信息和服务元数据,以支持高可用部署。**
好的,那么其实基于上面的分析,我们就已经可以大致的得到我们设计一个网关所需要的一些技术上的方向了,接下来的就是确定这些技术,并且确定自己设计该网关时的一个架构图了。
# 追本溯源:什么是网关?
现在来一手峰回路转,在上面一节中我们已经分析出来了设计要点,定了一个大概的设计方向,那么接下来我们想要真的开始设计,就得了解一个最最最基本的知识,就是网关,到底是什么?他的作用是什么?以及,接收到一个请求之后,他是如何对请求进行处理的呢?如何进行所谓的负载均衡和请求转发的呢?
所以,我们先Google一下网关的定义和概念,就有了如下内容:
[什么是网关,以及网关的作用是什么?](https://zhuanlan.zhihu.com/p/165142303)
> 网关(Gateway)又称网间连接器、协议转换器。网关在**传输层**上以实现网络互连,是最复杂的网络互连设备,仅用于两个**高层协议不同的**网络互连。网关的结构也和路由器类似,**不同的是互连层**。网关既可以用于广域网互连,也可以用于局域网互连。 网关是一种充当**转换**重任的计算机系统或设备。在使用不同的通信协议、数据格式或语言,甚至体系结构完全不同的两种系统之间,网关是一个**翻译器**。与网桥只是简单地传达信息不同,网关对收到的信息要重新打包,以适应目的系统的需求。同时,网关也可以提供**过滤和安全**功能。大多数网关运行在OSI 7层协议的顶层--应用层。
我们对网关的作用做一个总结,大概就是:
**协议转换、安全鉴权、日志监控、熔断限流、负载均衡 、请求转发**
没想到一个小小的网关居然有这么多的作用,这里我们就可以形成对上一节的呼应了,上节列出的七点是否顺利的和这里的七点做了一些关联呢?
而其实我们的一个请求被网关的处理流程,就和上面的流程差不多。
当网关收到客户端的请求时,它通常会执行以下步骤处理该请求:
1. **请求识别**:解析请求的头部、方法和路径,确定请求的服务和操作。
2. **安全检查**:应用安全层面的检查,可能包括解密SSL请求、验证API密钥、进行OAuth校验等。
3. **路由决策**:根据预定的路由规则或服务发现机制决定将请求发送到哪个服务。
4. **修改请求**:根据需要,修改请求的头部或查询参数,甚至请求体。
5. **负载均衡**:选择一个或多个目标服务实例,可能基于轮询、最少连接、服务器响应时间或哈希等策略。
6. **请求转发**:将请求转发到选定的后端服务。
7. **响应处理**:从后端服务接收响应,可能需要进行转换或重新格式化,然后将其返回给客户端。
8. **日志记录**:记录请求和响应的详细信息,用于审计和分析。
所以我们就能很明确的明白了一个网关所需要做的事情,也就明白了我们设计上需要着重考虑的一些点。而这些点就是影响网关功能甚至性能的关键。
# 架构分析与思考
## 技术栈选择
从上一节我们已经了解到一个网关设计过程中所需要考虑到的几乎方方面面的侧重点。那么我们接下来就基于这些侧重点分析如何对这些侧重点进行技术选型,并设计出我们的网关的一个大致的架构。
**性能与可伸缩性:**
参考目前主流的网关的设计,有SpringCloud Gateway以及Zuul,他们的底层都大量使用了异步编程的思想,并且也都有非常重要的网络通信上的设计。
比如我当初看SpringCloudGateway的源码的时候就看到了大量的对Netty的使用。
由于我们的网关是自研的,也就是他自己本身就是一个单独的服务,因此我们并不需要使用到SpringBoot这种框架,我们可以直接使用原生Java框架来编写各种重要代码。
因此网络通信上毋庸置疑的使用Netty即可。
缓存以及高性能这方面,分布式缓存我们使用Redis,本地缓存选择Caffeine,两者都是经过市场考验的成熟缓存框架。并且使用的用户量也更多。
**安全性上:**
我们使用JWT,其优点在于简单的Token格式,便于跨语言和服务传递,适合于微服务和分布式系统的安全性设计。
当然缺点也在于我们需要精细的管理和保护我们的密钥。
这里我并不打算支持TLS/SSL,首先是我作为个人开发者,想要去支持TLS/SSL是比较复杂的,并且我还需要管理证书的生命周期,会影响项目开发的进度,因此我并不打算在我的网关中支持TLS/SSL。
**可观测性:**
- **Micrometer** 和 **Dropwizard Metrics**:
- 优点: 两者都是成熟的度量收集框架,提供了丰富的度量集合和报告功能。
- 缺点: 可能需要适配特定的监控系统或标准。
- **ELK Stack**:
- 优点: 提供了一个完整的日志分析解决方案,适用于大规模日志数据的收集、搜索和可视化。
- 缺点: 组件较多,搭建和维护相对复杂。
- **Prometheus** 和 **Grafana**:
- 优点: 高度适合于时序数据监控,Grafana 提供强大的数据可视化。
- 缺点: 需要配置和维护Prometheus数据抓取和存储。
这里我选择使用最后一种,因为目前市面上这种用的比较多,我也比较熟悉,我就职过多公司也基本都是这一套。并且Prometheus相对于其他的更加简单易用。
**路由能力/高可用:**
同时,在上文也提到了,网关是需要用到注册中心的,因为我们的请求具体最后要转发到那个路由,是需要从注册中心中拉取服务信息的,目前注册中心有:**Zookeeper,Eureka,Nacos,Apollo,etcd,Consul**
他们各有优劣势,比如Zk保证的是CP而不是AP,我们知道,网关是应用的第一道门户,我们使用Dubbo的时候会使用Zk,但是对于网关,可用性大于一致性,因此Zk我们不选。
而Eureka都和SpringCloud生态有比较紧密的联系,因此如果我们使用它,就会增加我们的网关和SpringCloud的耦合,不太符合我们自研的初衷,所以也不选。
Etcd虽然是通用的键值对分布式存储系统,可以很好的应用于分布式系统,但是依旧没有很好的优势,当然,他很轻量级。所以这里暂不考虑。
Consul和Etcd差不多,所以这里也不考虑Consul。
这里我选用Nacos作为注册中心,Nacos首先支持CP和AP协议,并且提供了很好的控制台方便我对服务进行管理。同时,Nacos的社区相对来说非常活跃,网络上的资料也更加的多,同时,我也看过Nacos的源码,编写优雅且相对易懂。同时我相信会使用Nacos的人肯定更多,因此在这里选择Nacos作为注册中心。
当然,上面的几种注册中心都可以使用,没有特别明显的优劣势,他们也都有各自合适的场合,具体场合具体分析,主要是要分析自己的团队更加了解或者适合哪一种注册中心。
而配置中心方面,有SpringCloud Config,Apollo,Nacos。
这里很明显,依旧选择Nacos,因为Nacos不仅仅是注册中心也是配置中心。因此选用Nacos我们可以减少引入不必要的第三方组件。
**多协议支持:**
可以考虑的有gRPC和Dubbo,gRPC支持多种语言,并且基于HTTP/2.0,Dubbo在Alibaba使用的比较多,并且比较适合Java的生态。同时gRPC的使用要求熟悉Protobuf,所以这里为了减少成本,考虑使用Dubbo。
所以,经过一套分析,我们就可以得出如下的主要技术栈:
1. **开发语言:Java 19**
2. **网络通信框架:Netty 4.1.51**
3. **缓存:Redis、Caffeine 版本不限**
4. **注册中心与配置中心:Naccos 2.0.4**
5. **RPC协议:Dubbo 2.7.x**
6. **日志监控:Prometheus、Grafana 版本不限**
7. **安全鉴权:JWT 版本不限**
## 项目架构
基于技术栈的分析完毕之后,我们就可以开始考虑如何对项目的架构进行设计了,思考每个服务的实现方式,比如我们的网关如何处理每一个请求?走的是过滤器对吗?我们的网关如何进行请求转发?需要先从注册中心拿到服务实例对吗?我们需要一个实体类来代表我们的请求和响应对吗?我们需要用到什么机制来动态的加载我们的配置?我们需要如何判定什么时候需要加载什么类?什么时候什么路径下某个过滤器才会生效?
这些都是我们需要考虑的,所以,我们画出如下架构图:
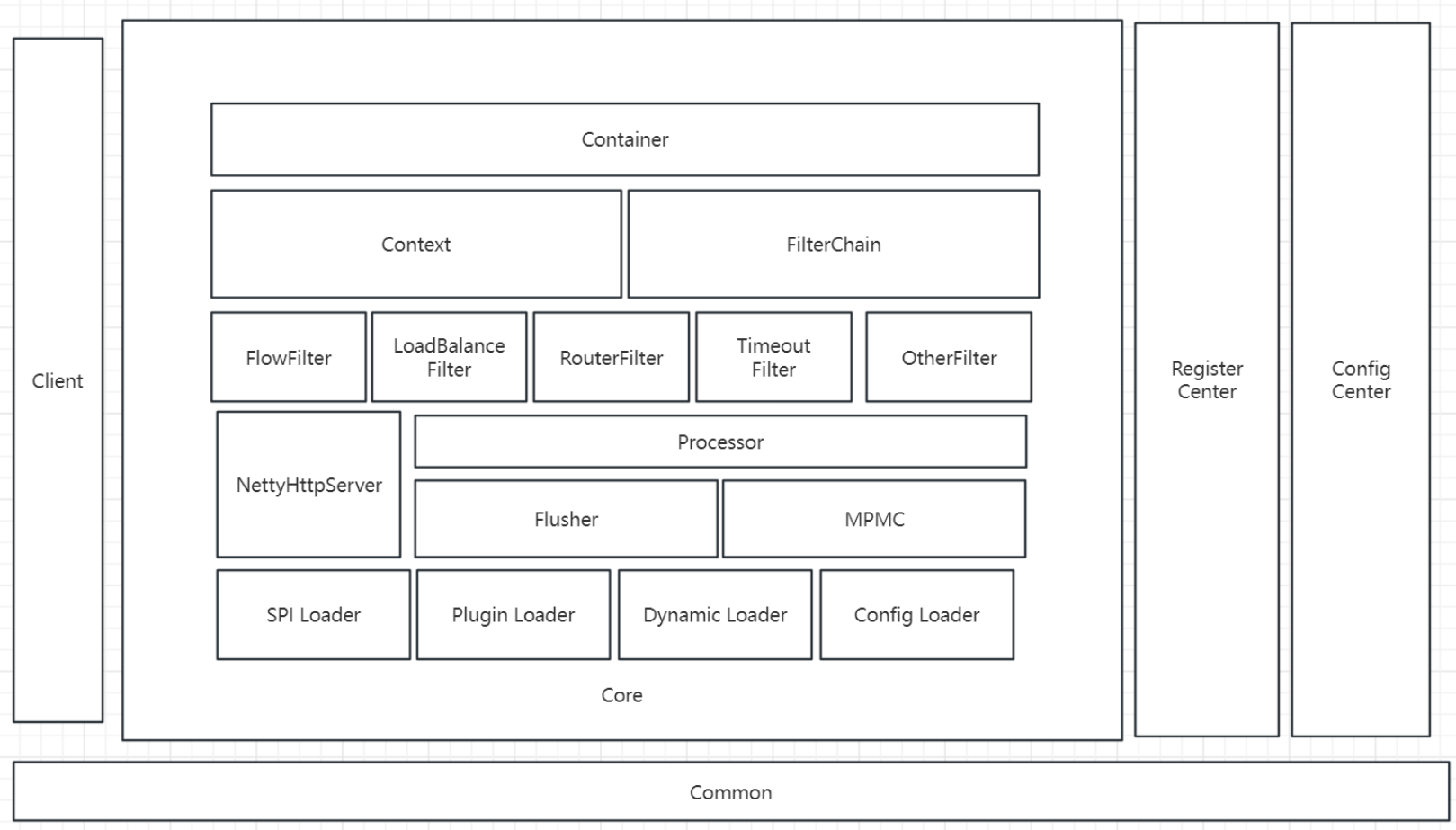
Common:维护公共代码,比如枚举
Client:客户端模块,方便我们其他模块接入网关
Register Center:注册中心模块
Config Center:配置中心模块
Container:包含核心功能
Context:请求上下文,规则
FilterChain:通过责任链模式,链式执行过滤器
FlowFilter:流控过滤器
LoadBalanceFilter:负载均衡过滤器
RouterFilter:路由过滤器
TimeoutFilter:超时过滤器
OtherFilter:其他过滤器
NettyHttpServer:接收外部请求并在内部进行流转
Processor:后台请求处理
Flusher:性能优化
MPMC:性能优化
SPI Loader:扩展加载器
Plugin Loader:插件加载器
Dynamic Loader:动态配置加载器
Config Loader:静态配置加载器
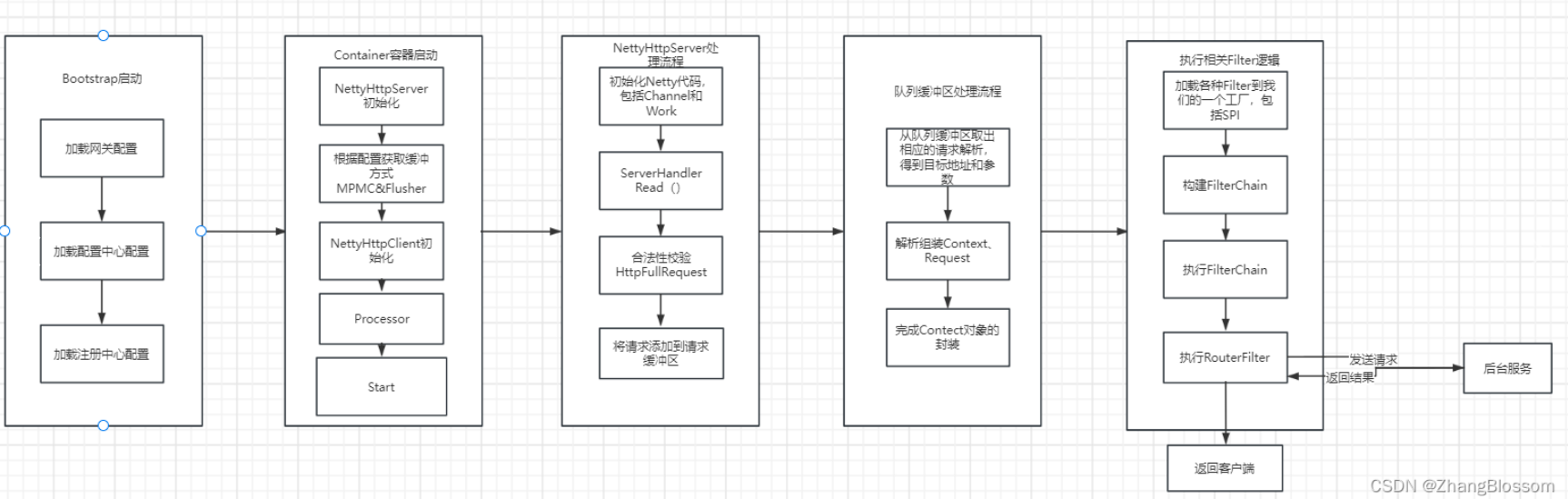
## 处理流程
根据上面的分析,我们可以得到如下的一个处理流程。
# 项目骨架的搭建
在上一节中已经设定好了大致的网关架构所需要用到的一些服务,比如Common、Register Center、Config Center、Client、Core等模块,那么我们就按照这样子框架先搭建出来一个项目骨架
搭建完毕之后,项目骨架如下:

经过上一章节的讲解,我想只需要根据我们的目录名称就可以大概知道这些目录的作用。
但是我还是打算介绍一下这些目录。
- Client:网关服务客户端,提供了一些注解用于注册对应的服务到网关中。
- Common:网关通用模块包,存放通用配置以及一些工具类。
- ConfigCenter:网关配置中心,当前包提供基于Nacos服务的配置中心的功能,负责从配置中心拉取对应的配置。
- RegisterCenter:网关注册中心,用于将网关服务注册到基于Nacos的注册中心。
- Core:网关核心模块,网关的几乎所有功能以及网关的启动都依赖于这个模块,包含了过滤器、启动容器、Netty网络处理框架等核心代码。
- HttpServer:测试网关HTTP请求服务模块。
- UserServer:测试网关JWT安全鉴权服务模块。
- Dubbo:提供网关基于Dubbo的RPC远程服务调用实现(暂未开发)。
# 前置知识
## ServiceLoader
由于我的项目不是基于Spring实现的网关,那么也就意味着我需要手动的进行一些类的加载,那么这个时候时候我就需要一种机制,它可以帮助我按照我的配置来加载一些我需要的类,就有点类似于SpringBoot的spring.factory自动配置文件,通过扫描这个配置文件中的信息来动态的加载我项目所需要的类。
这里我是用的就是ServiceLoader了。
具体的ServiceLoader的用法比较简单,这里就简单描述一下:
在你需要用到某些你需要加载的类的时候,比如我需要加载过滤器,那么我就给出这个过滤器的类信息。然后再我们的resource目录下,创建META-INF/services目录。
目录下创建文件,文件名称为你需要加载的接口的全类名。
文件中包含的就是该接口实现类的全类名,如下:
```
ServiceLoader serviceLoader = ServiceLoader.load(Filter.class);
```
## 熔断、限流、服务降级的区别
熔断、限流和服务降级是微服务架构中常用的三种弹性设计模式,它们虽然都旨在提高系统的稳定性和可靠性,但各自的工作机制和应用场景有所不同。所以这里我们先来了解一下他们的区别。
1. **熔断 (Circuit Breaking)**:
- 熔断器模式的核心思想是防止连锁故障。当系统中的一个组件出现错误,如超时或响应失败,熔断器会“断开”,阻止进一步的调用。
- 熔断的目的是给予故障服务时间进行恢复,同时防止故障扩散到其他服务。
- 熔断器通常有几个状态:关闭、打开(熔断)和半开。在半开状态下,熔断器允许有限的调用数通过,以检测故障服务是否恢复正常。
2. **限流 (Rate Limiting)**:
- 限流是控制系统接收的请求数量或者进行的操作数以防止系统过载的过程。
- 它确保系统只处理它能够处理的最大请求数量,防止资源耗尽(如内存、带宽或数据库连接)。
- 限流可以根据固定的限制,如每秒请求次数(QPS),或动态的限制,如根据系统的当前性能调整。
3. **服务降级 (Degradation)**:
- 服务降级是当系统处于高负载或部分服务不可用时,主动降低某些功能的质量或关闭非核心功能,以保证核心功能的运行。
- 这可以通过返回一个简化的或默认的响应来实现,或者关闭一些非关键的服务。
- 服务降级的目的是在资源有限的情况下,优先保证关键服务的可用性和稳定性。
我简单总结一下:
- **熔断**是一种保护机制,当检测到服务失败时,它会暂停服务的调用,以防止故障扩散。
- **限流**是一种控制机制,用于控制进入系统的流量,以防止系统过载。
- **服务降级**是一种应对策略,当系统资源紧张时,通过降低服务质量或功能来保持系统的核心部分运行。
有了这些前置知识,我们就可以开始进行具体的设计了。首先是限流,这个是最简单的。
## JWT
JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在各方之间安全地传输信息作为 JSON 对象。它通常用于在不同系统之间进行身份验证和授权,以及在各种应用中传递声明性信息。
JWT 由三部分组成,它们通过点号(.)分隔:
- Header(头部):包含了关于生成的 JWT 的元数据信息,例如算法和令牌类型。
- Payload(负载):包含了实际的声明(claim)信息,这些声明是关于实体(通常是用户)和其他数据的信息。有三种类型的声明:注册声明、公共声明和私有声明。
- Signature(签名):用于验证JWT的完整性,确保数据在传输过程中没有被篡改。签名是基于头部和负载,使用一个密钥(秘密或公开的)进行加密生成的。
JWT 的作用包括:
- 身份验证:JWT可用于验证用户身份,确保请求来自经过身份验证的用户。用户登录后,可以生成JWT并将其存储在客户端,然后在后续请求中使用它来证明身份。
- 授权:JWT可以包含用户的授权信息,以便在服务器端验证用户是否有权限执行某个操作或访问某个资源。
- 信息交换:JWT可用于在不同系统之间安全地传递信息,例如在微服务架构中进行服务之间的通信。
本项目中使用jjwt实现JWT功能。
```
io.jsonwebtoken
jjwt
0.6.0
```
之后我们编写一个简单的测试用例
```
@Test
public void jwt() {
// 定义一个密钥用于签名 JWT
String security = "zhangblossom";
// 创建一个 JWT Token
String token = Jwts.builder()
.setSubject("1314520") // 设置JWT的主题,通常为用户的唯一标识
.setIssuedAt(new Date()) // 设置JWT的签发时间,通常为当前时间
.signWith(SignatureAlgorithm.HS256, security) // 使用HS256算法签名JWT,使用密钥"security"
.compact(); // 构建JWT并返回字符串表示
// 打印生成的JWT Token
System.out.println(token);
// 解析JWT Token
Jwt jwt = Jwts.parser().setSigningKey(security).parse(token);
// 打印解析后的JWT对象
System.out.println(jwt);
// 从JWT中获取主题(Subject)信息
String subject = ((DefaultClaims) jwt.getBody()).getSubject();
// 打印JWT中的主题信息
System.out.println(subject);
}
```
JWT鉴权的架构流程图
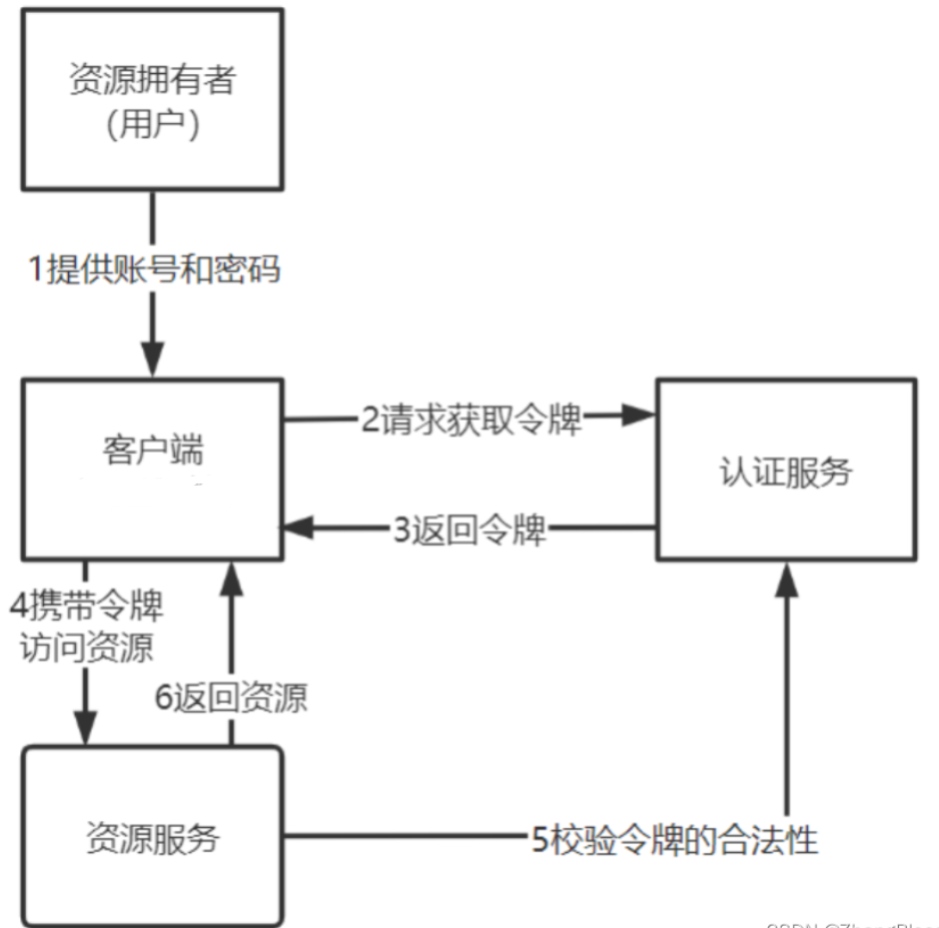
1、客户端携带令牌访问资源服务获取资源。
2、资源服务远程请求认证服务校验令牌的合法性
3、如果令牌合法资源服务向客户端返回资源。
这里存在一个问题:
就是校验令牌需要远程请求认证服务,客户端的每次访问都会远程校验,执行性能低。
如果能够让资源服务自己校验令牌的合法性将省去远程请求认证服务的成本,提高了性能。如下图:
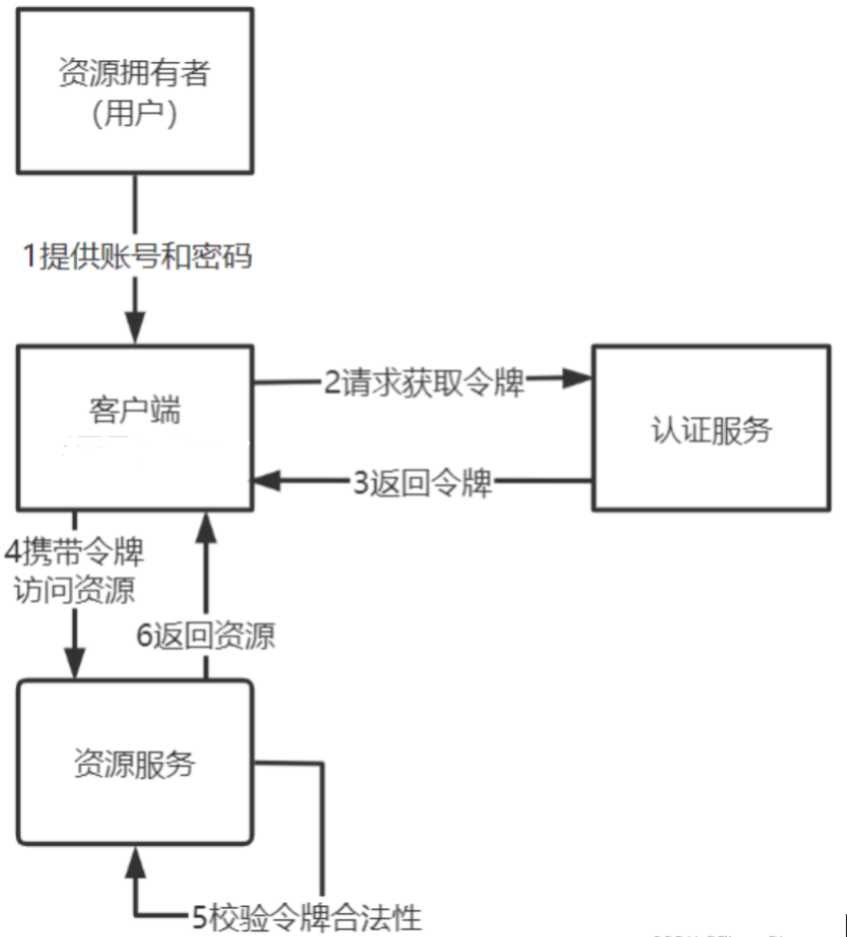
牌采用JWT格式即可解决上边的问题,用户认证通过后会得到一个JWT令牌,JWT令牌中已经包括了用户相关的信息,客户端只需要携带JWT访问资源服务,资源服务根据事先约定的算法自行完成令牌校验,无需每次都请求认证服务完成授权。
接下来的代码,我们就要求用户首先请求login用户登录接口,用来得到我们的JWT的token信息,并且我们会将这个token信息写入到我们的请求头中。
之后,当我们请求其他需要使用到token信息的接口的时候,我们就可以从请求头中获取到当前的用户信息了。
## 灰度发布
先简单介绍一下什么是灰度发布
> 灰度发布(Gray Release)是一种软件部署和发布策略,用于逐步将新版本的应用或服务引入生产环境,以降低潜在的风险并确保系统的稳定性。在灰度发布中,新版本的应用或服务不会一次性全部暴露给所有用户,而是逐渐引入一小部分用户,然后根据观察结果决定是否继续推广新版本或回滚到旧版本。这种策略有助于在生产环境中验证新功能、修复潜在问题以及逐渐接受用户反馈。
>
> 关键特点和概念:
>
> 渐进式发布:新版本逐渐替代旧版本,从一小部分用户开始,然后逐渐增加新版本的暴露范围。这可以是一个逐步增加百分比的用户,也可以是按照某种规则或条件选择的用户群体。
>
> 风险控制:通过逐渐发布,可以在早期发现和解决潜在问题,从而减轻生产环境中可能发生的故障或问题对整体系统的影响。
>
> 用户反馈:灰度发布过程中,可以收集用户的反馈和性能数据,帮助开发团队更好地了解新版本的行为和性能,以及用户的满意度。
>
> 回滚能力:如果在灰度发布期间发现了严重问题或故障,可以轻松回滚到旧版本,从而减少对用户和业务的负面影响。
>
> 分层策略:通常,灰度发布采用多层级策略,从开发环境到测试环境,再到生产环境,逐渐扩大发布的范围。这确保了新版本在不同环境中都经历了测试和验证。
>
> 自动化工具:灰度发布通常借助自动化工具和部署管道来简化流程,例如使用容器编排工具、部署蓝绿或金丝雀发布等。
>
> 灰度发布是现代软件开发和交付的一种最佳实践,它允许组织更加安全和可控地推出新功能,降低风险,提高可维护性,同时减少对用户的影响。这是特别适用于大规模和高可用性系统的策略,以确保系统的连续性和稳定性。
之后再来介绍一下:**全链路灰度发布**
> 全链路发布是一种软件交付策略,它强调在整个软件开发和交付过程中的每个环节都进行逐步验证和控制,以确保新版本的成功发布并降低风险。全链路发布覆盖了整个软件生命周期,包括开发、测试、部署、监控、用户反馈和持续改进等阶段。
灰度发布注重的是部署发布这个过程,而全链路发布则范围更加广,包含了开发的整个生命周期,从开发,测试,到部署,维护等。
## Mock
> Mock(模拟)是一种测试技术,用于创建虚拟对象来模拟真实对象的行为。Mock对象模拟了真实对象的行为,但是不依赖于真实对象的实现细节。它们可以在测试中替代真实对象,以便进行独立的单元测试。
>
> 需要使用Mock的原因包括以下几点:
>
> 依赖项不可用:在进行单元测试时,某些依赖项可能无法访问或不可用,例如数据库、网络服务等。使用Mock对象可以模拟这些依赖项的行为,使测试能够独立运行。
>
> 控制测试环境:使用Mock对象可以控制测试环境中的各种情况和条件,例如模拟错误、异常、超时等,以确保代码在各种情况下的正确性和稳定性。
>
> 提高测试性能:某些依赖项可能是耗时的操作,例如数据库查询、网络请求等。使用Mock对象可以避免这些耗时操作,提高测试的执行速度。
>
> 隔离测试:使用Mock对象可以将被测试对象与其依赖项进行隔离,确保测试的独立性。这样可以更容易地定位和调试问题,同时也提高了测试的可维护性。
>
> Mock对象在单元测试中扮演了替代真实对象的角色,使得测试更加独立、可控和高效。通过使用Mock对象,开发人员可以更好地测试代码的各种情况和边界条件,提高软件的质量和可靠性。
>
>
# 配置加载类设计
上面我们已经对网关项目的各个模块都进行了了解了,那么接下来我们要做的事情就是去动手实现。
再上面的架构设计中我们已经提出,我们的项目需要提供足够的扩展性,方便我们的项目运行时支持各类配置,因此,我们首先从配置这一块下手。
最基础的,我们首先设计一个类用于为网关提供配置,这个类支持我们的项目从配置文件、JVM参数、运行时参数、环境变量中进行我们配置的读取。
对于配置加载类的设计就有点像我们SpringBoot项目了,都会在启动的时候按照约定读取特定的配置文件进行加载。
那么Java也为我们提供了许多非常方便的从不同地方读取配置信息的API。
这里我们直接看代码,代码比较容易理解。
```
package blossom.project.core;
import blossom.project.common.utils.PropertiesUtils;
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.io.InputStream;
import java.util.Map;
import java.util.Properties;
/**
* 配置加载类
*/
@Slf4j
public class ConfigLoader {
private static final String CONFIG_FILE = "gateway.properties";
private static final String ENV_PREFIX = "GATEWAY_";
private static final String JVM_PREFIX = "gateway.";
private static final ConfigLoader INSTANCE = new ConfigLoader();
private ConfigLoader() {}
public static ConfigLoader getInstance() {
return INSTANCE;
}
private Config config;
public static Config getConfig() {
return INSTANCE.config;
}
/**
* 优先级高的会覆盖优先级低的
* 运行参数 -> jvm参数 -> 环境变量 -> 配置文件 -> 配置对象对默认值
* @param args
* @return
*/
public Config load(String args[]) {
//配置对象对默认值
config = new Config();
//配置文件
loadFromConfigFile();
//环境变量
loadFromEnv();
//jvm参数
loadFromJvm();
//运行参数
loadFromArgs(args);
return config;
}
private void loadFromArgs(String[] args) {
//--port=1234
if (args != null & args.length > 0) {
Properties properties = new Properties();
for (String arg : args) {
if (arg.startsWith("--") && arg.contains("=")) {
properties.put(arg.substring(2, arg.indexOf("=")),
arg.substring(arg.indexOf("=") + 1));
}
}
PropertiesUtils.properties2Object(properties, config);
}
}
private void loadFromJvm() {
Properties properties = System.getProperties();
PropertiesUtils.properties2Object(properties, config, JVM_PREFIX);
}
private void loadFromEnv() {
Map env = System.getenv();
Properties properties = new Properties();
properties.putAll(env);
PropertiesUtils.properties2Object(properties, config, ENV_PREFIX);
}
private void loadFromConfigFile() {
InputStream inputStream = ConfigLoader.class.getClassLoader().getResourceAsStream(CONFIG_FILE);
if (inputStream != null) {
Properties properties = new Properties();
try {
properties.load(inputStream);
PropertiesUtils.properties2Object(properties, config);
} catch (IOException e) {
log.warn("load config file {} error", CONFIG_FILE, e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
//
}
}
}
}
}
}
```
这里的代码其实就是按顺序读取各个地方的配置,并且按照优先级顺序,高优先级会覆盖低优先级的配置。
最后读取完毕所有的配置之后得到一个Config类,这个就是当前我们项目的配置信息了。
下面附上配置方法。

# 基于Netty的网络通信层设计
## Netty概述
在基于Netty进行设计之前,我们先按照老方法,介绍一下Netty,以及它的作用和使用场景。
1. **Netty 是什么**: Netty 是一个高性能的、异步事件驱动的网络应用程序框架,支持快速开发可维护的高性能协议服务器和客户端。它是一个在 Java NIO 的基础上构建的网络编程框架,提供了易于使用的API。
2. **Netty 的具体功能**:
3. **异步和事件驱动**:Netty 提供了一个多线程的事件循环,用于处理所有网络事件,例如连接、数据发送和接收。
4. **支持多协议**:它可以支持多种传输协议,包括 TCP、UDP,以及更高级的协议如 HTTP、HTTPS、WebSocket。
5. **高度可定制**:可以通过ChannelHandler来定制处理网络事件的逻辑,支持编解码器、拦截器等。
6. **性能优化**:利用池化和复用技术来减少资源消耗,减少GC压力,优化内存使用。
7. **安全性**:内置了对 SSL/TLS 协议的支持,确保数据传输安全。
3. **Netty 中的核心概念**:
- **Boss 和 Worker 线程**:在 Netty 的服务器端,"Boss" 线程负责处理连接的建立,而 "Worker" 线程负责处理已连接的通道的IO操作。这种模型允许Boss线程迅速处理新的连接,并将数据传输的处理任务委托给Worker线程。
- **Channel**:代表一个到远程节点的开放连接,可以进行读写操作。
- **EventLoop**:用于处理连接的生命周期中的所有事件,每个Channel都分配给了一个EventLoop。
- **ChannelHandler**:核心处理器,可以响应入站和/或出站事件和数据。
4. **Netty 的使用场景**:
- **Web服务器和客户端**:使用Netty作为底层通信组件来构建自己的Web服务器和HTTP客户端。
- **实时通信系统**:如在线游戏的服务器、聊天服务器,因为Netty支持WebSocket和TCP协议,适合需要低延迟和大量并发连接的应用。
## 服务端实现
首先,在 Maven `pom.xml` 文件中引入Netty的依赖:
```java
io.netty
netty-all
4.1.59.Final
```
在基于 Netty设计服务端之前我们首先需要了解一下几个Netty中的核心概念:
1. `**EventLoopGroup**`: 这是Netty中的一个核心组件,负责处理所有的I/O操作。`EventLoopGroup`是一个包含多个`EventLoop`的组,每个`EventLoop`都是一个单线程循环,负责处理连接的生命周期内的所有事件。其分为boss和worker两种类型的线程组。boss线程组通常负责接受新的客户端连接,而worker线程组负责处理boss线程组接受的连接的后续I/O操作。
2. `**ServerBootstrap**`: 这个类是一个帮助类,用于设置服务器。它允许我们设置服务器所需的所有参数,如端口、使用的`EventLoopGroup`等。`ServerBootstrap`还允许为新接受的连接以及连接后的通道设置属性和处理程序。
3. `**Channel**`: `Channel`接口代表一个到远程节点的开放连接,可以进行读写操作。在Netty中,`Channel`是网络通信的基础组件,每个连接都会创建一个新的`Channel`。
4. `**ChannelInitializer**`: 这是一个特殊的处理程序,用于配置新注册的`Channel`的`ChannelPipeline`,它提供了一个容易扩展的方式来初始化`Channel`,一旦`Channel`注册到`EventLoop`上,就会调用`ChannelInitializer`。
5. `**ChannelPipeline**`: 这个接口表示一个`ChannelHandler`的链表,用于处理或拦截入站和出站操作。它使得可以容易地添加或删除处理程序。
6. `**ChannelHandler**`: 接口定义了很多事件处理方法,你可以通过实现这些方法来进行自定义的事件处理。事件可以是入站也可以是出站的,例如数据读取、写入、连接开启和关闭。
7. `**ChannelHandlerContext**`: 提供了一个接口,用于在`ChannelHandler`中进行交互操作。通过这个上下文对象,处理程序可以传递事件、修改管道、存储处理信息等。
8. `**ChannelOption**` 和 `**ChannelConfig**`: 这些类和接口用于配置`Channel`的参数,如连接超时、缓冲区大小等。
9. `**NioEventLoopGroup**` 和 `**EpollEventLoopGroup**`: 这些类是`EventLoopGroup`的实现,分别对应于使用Java NIO和Epoll(只在Linux上可用)作为传输类型。Netty自动选择使用哪个实现,通常基于操作系统的能力和应用程序的需求。
10. `**NioServerSocketChannel**` 和 `**EpollServerSocketChannel**`: 这些是`Channel`实现,表示服务器端的套接字通道。选择哪个实现通常取决于你选择的`EventLoopGroup`。
11. **编解码器(**`**Codec**`**)**: Netty提供了一系列的编解码器用于数据的编码和解码,例如`HttpServerCodec`用于HTTP协议的编码和解码。
在你已经大致的知道了设计一个Netty客户端所涉及到的一些知识之后,我们来基于代码进行分析。
```java
package blossom.project.core.netty;
import blossom.project.common.utils.RemotingUtil;
import blossom.project.core.Config;
import blossom.project.core.LifeCycle;
import blossom.project.core.netty.processor.NettyProcessor;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.Channel;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelOption;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.epoll.Epoll;
import io.netty.channel.epoll.EpollEventLoopGroup;
import io.netty.channel.epoll.EpollServerSocketChannel;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.codec.http.HttpObjectAggregator;
import io.netty.handler.codec.http.HttpServerCodec;
import io.netty.handler.codec.http.HttpServerExpectContinueHandler;
import io.netty.util.concurrent.DefaultThreadFactory;
import lombok.Getter;
import lombok.extern.slf4j.Slf4j;
import java.net.InetSocketAddress;
/**
* Netty的Server端实现
*/
// 类注解和作者信息
@Slf4j
public class NettyHttpServer implements LifeCycle {
// 服务器配置对象,用于获取如端口号等配置信息
private final Config config;
// 自定义的Netty处理器接口,用于定义如何处理接收到的请求
private final NettyProcessor nettyProcessor;
// 服务器引导类,用于配置和启动Netty服务
private ServerBootstrap serverBootstrap;
// boss线程组,用于处理新的客户端连接
private EventLoopGroup eventLoopGroupBoss;
// worker线程组,用于处理已经建立的连接的后续操作
@Getter
private EventLoopGroup eventLoopGroupWoker;
// 构造方法,用于创建Netty服务器实例
public NettyHttpServer(Config config, NettyProcessor nettyProcessor) {
this.config = config;
this.nettyProcessor = nettyProcessor;
init(); // 初始化服务器
}
// 初始化服务器,设置线程组和选择线程模型
@Override
public void init() {
this.serverBootstrap = new ServerBootstrap();
// 判断是否使用Epoll模型,这是Linux系统下的高性能网络通信模型
if (useEpoll()) {
this.eventLoopGroupBoss = new EpollEventLoopGroup(config.getEventLoopGroupBossNum(),
new DefaultThreadFactory("epoll-netty-boss-nio"));
this.eventLoopGroupWoker = new EpollEventLoopGroup(config.getEventLoopGroupWokerNum(),
new DefaultThreadFactory("epoll-netty-woker-nio"));
} else {
// 否则使用默认的NIO模型
this.eventLoopGroupBoss = new NioEventLoopGroup(config.getEventLoopGroupBossNum(),
new DefaultThreadFactory("default-netty-boss-nio"));
this.eventLoopGroupWoker = new NioEventLoopGroup(config.getEventLoopGroupWokerNum(),
new DefaultThreadFactory("default-netty-woker-nio"));
}
}
// 检测是否使用Epoll优化性能
public boolean useEpoll() {
return RemotingUtil.isLinuxPlatform() && Epoll.isAvailable();
}
// 启动Netty服务器
@Override
public void start() {
// 配置服务器参数,如端口、TCP参数等
this.serverBootstrap
.group(eventLoopGroupBoss, eventLoopGroupWoker)
.channel(useEpoll() ? EpollServerSocketChannel.class : NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024) // TCP连接的最大队列长度
.option(ChannelOption.SO_REUSEADDR, true) // 允许端口重用
.option(ChannelOption.SO_KEEPALIVE, true) // 保持连接检测
.childOption(ChannelOption.TCP_NODELAY, true) // 禁用Nagle算法,适用于小数据即时传输
.childOption(ChannelOption.SO_SNDBUF, 65535) // 设置发送缓冲区大小
.childOption(ChannelOption.SO_RCVBUF, 65535) // 设置接收缓冲区大小
.localAddress(new InetSocketAddress(config.getPort())) // 绑定监听端口
.childHandler(new ChannelInitializer() { // 定义处理新连接的管道初始化逻辑
@Override
protected void initChannel(Channel ch) throws Exception {
// 配置管道中的处理器,如编解码器和自定义处理器
ch.pipeline().addLast(
new HttpServerCodec(), // 处理HTTP请求的编解码器
new HttpObjectAggregator(config.getMaxContentLength()), // 聚合HTTP请求
new HttpServerExpectContinueHandler(), // 处理HTTP 100 Continue请求
new NettyHttpServerHandler(nettyProcessor), // 自定义的处理器
new NettyServerConnectManagerHandler() // 连接管理处理器
);
}
});
// 绑定端口并启动服务,等待服务端关闭
try {
this.serverBootstrap.bind().sync();
log.info("server startup on port {}", this.config.getPort());
} catch (Exception e) {
throw new RuntimeException("启动服务器时发生异常", e);
}
}
// 关闭Netty服务器,释放资源
@Override
public void shutdown() {
if (eventLoopGroupBoss != null) {
eventLoopGroupBoss.shutdownGracefully(); // 优雅关闭boss线程组
}
if (eventLoopGroupWoker != null) {
eventLoopGroupWoker.shutdownGracefully(); // 优雅关闭worker线程组
}
}
}
```
大部分地方都比较容易理解,在init方法中我们初始化了EventLoopGroup来帮助我们处理我们的IO请求。
在start这个重点方法中我们基于ServerBootStrap进行了对Netty的配置。
我们依靠ChannelInitializer来添加通道处理类。
在这个ChannelInitializer中,只有两行代码是最重要的:
```java
new NettyHttpServerHandler(nettyProcessor), // 自定义的处理器
new NettyServerConnectManagerHandler() // 连接管理处理器
```
这行代码意味着进入到Netty通道中的请求需要被我的这个自定义的处理器类所处理。
所以我们来分析一下这个处理器类都起到了什么作用。
首先是先分析NettyHttpServerHandler这个类是什么,它的作用是什么:
```
public class NettyHttpServerHandler extends ChannelInboundHandlerAdapter {
// 成员变量nettyProcessor,用于处理具体的业务逻辑
private final NettyProcessor nettyProcessor;
/**
* 构造函数,接收一个 NettyProcessor 类型的参数。
*
* @param nettyProcessor 用于处理请求的业务逻辑处理器。
*/
public NettyHttpServerHandler(NettyProcessor nettyProcessor) {
this.nettyProcessor = nettyProcessor;
}
/**
* 当从客户端接收到数据时,该方法会被调用。
* 这里将入站的数据(HTTP请求)包装后,传递给业务逻辑处理器。
*
* @param ctx ChannelHandlerContext,提供了操作网络通道的方法。
* @param msg 接收到的消息,预期是一个 FullHttpRequest 对象。
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 将接收到的消息转换为 FullHttpRequest 对象
FullHttpRequest request = (FullHttpRequest) msg;
// 创建 HttpRequestWrapper 对象,并设置上下文和请求
HttpRequestWrapper httpRequestWrapper = new HttpRequestWrapper();
httpRequestWrapper.setCtx(ctx);
httpRequestWrapper.setRequest(request);
// 调用业务逻辑处理器的 process 方法处理请求
nettyProcessor.process(httpRequestWrapper);
}
/**
* 处理在处理入站事件时发生的异常。
*
* @param ctx ChannelHandlerContext,提供了操作网络通道的方法。
* @param cause 异常对象。
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
// 调用父类的 exceptionCaught 方法,它将按照 ChannelPipeline 中的下一个处理器继续处理异常
super.exceptionCaught(ctx, cause);
// 打印自定义消息,实际使用时应该记录日志或进行更复杂的异常处理
System.out.println("----");
}
}
```
ChannelInboundHandlerAdapter提供了一种简便的方式来帮助我们处理入站的网络事件。
其中channelRead比较重要,它可以帮助我解析和处理接收到的数据,因为在Netty中,消息通常是 `ByteBuf` 的形式,但也可以是任何我在 `ChannelPipeline` 中设置的解码器能够处理的类型。因此我可以在这个方法中实现我的业务逻辑,也可以调用业务逻辑处理器来处理我接受到的数据。
我们可以Debug看看这个发送一个请求的时候,在这个地方都发生了什么。
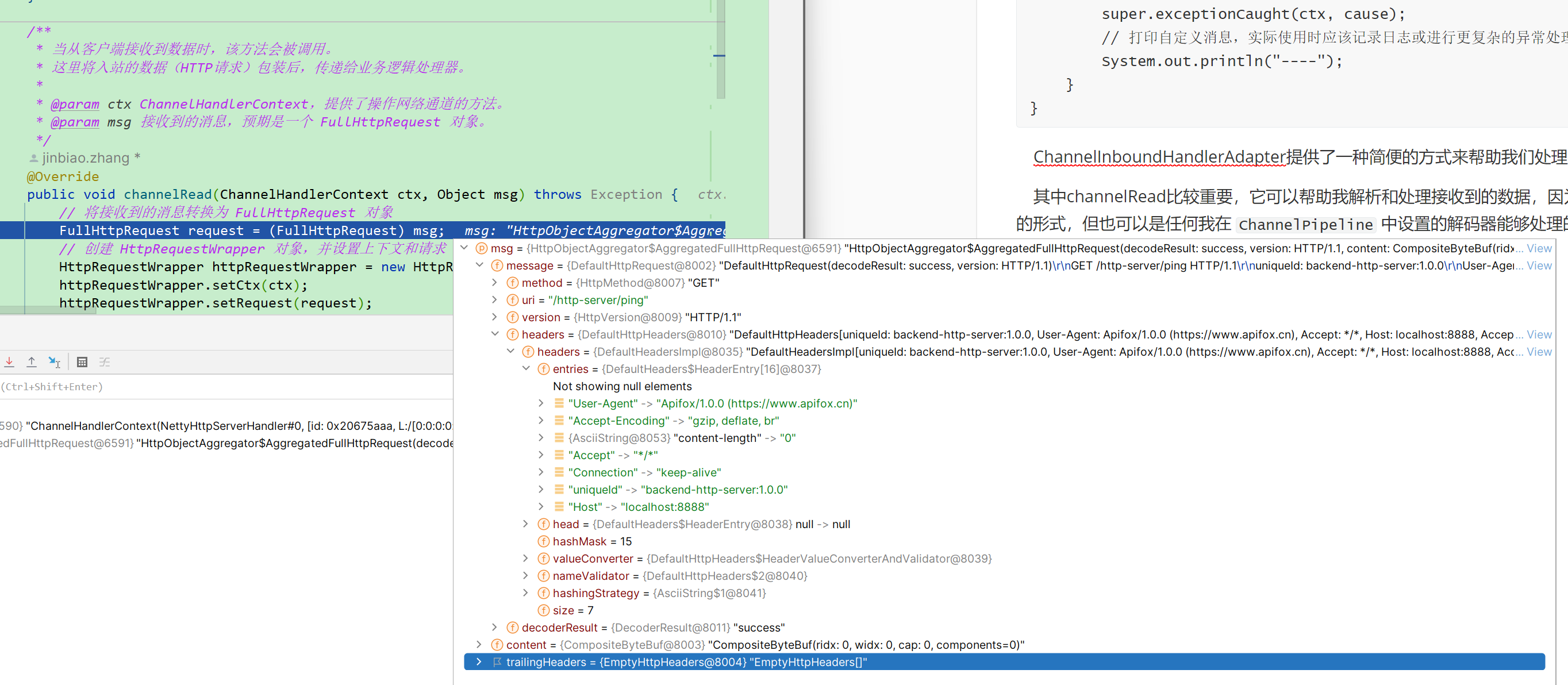
可以看到请求和FullHttpRequest有着巨大的关系,在Netty框架中,`FullHttpRequest` 类是一个接口,它代表了一个完整的HTTP请求。这个类的作用是封装了HTTP请求的所有部分,包括请求行(如方法GET/POST、URI、HTTP版本)、请求头(Headers)以及请求体(Body)。因此我们只要拿到了这个类的信息并且保存,我们就可以在后续随时的对这一次的请求信息进行分析并做出对应的处理
再来看看上面提到的ChannelHandlerContext。可以看到他有点类似于过滤器链,指向了下一个要处理当前请求的类。它的作用在上面我也已经讲解到了,详细的讲解就先留一个伏笔吧。
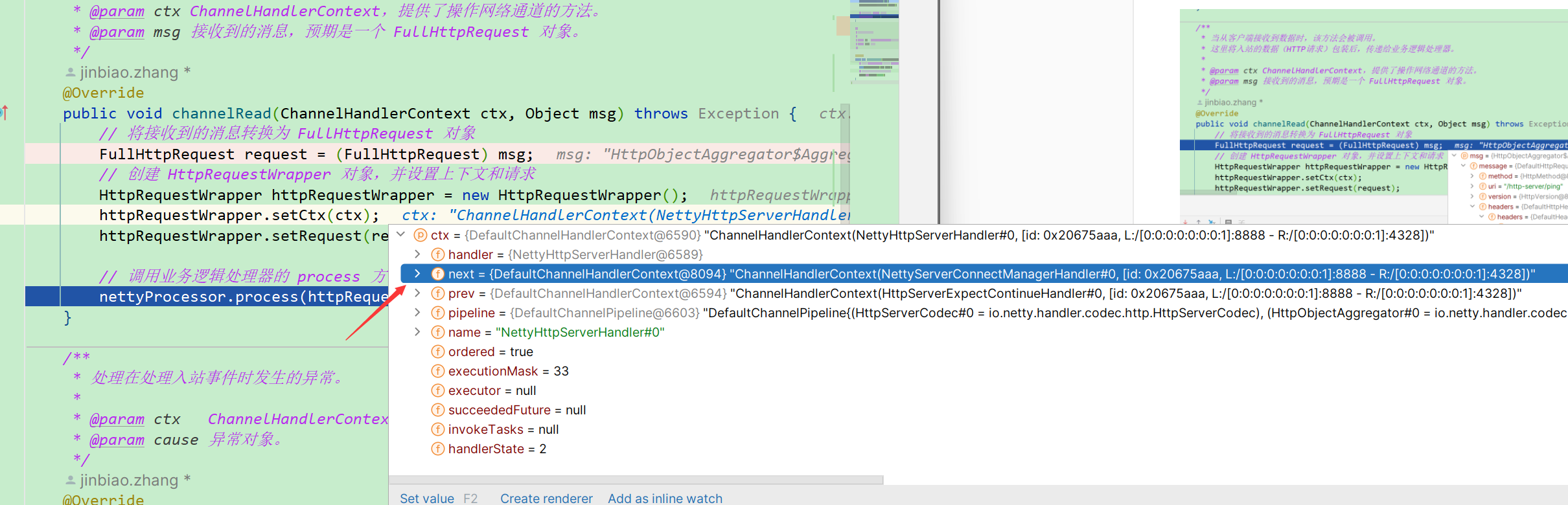
然后我们来分析这里的NettyProcessor这个接口的实现类的作用。
在没有使用Disruptor之前,我们来看看默认我的实现:
```java
@Override
public void process(HttpRequestWrapper wrapper) {
FullHttpRequest request = wrapper.getRequest();
ChannelHandlerContext ctx = wrapper.getCtx();
try {
// 创建并填充 GatewayContext 以保存有关传入请求的信息。
GatewayContext gatewayContext = RequestHelper.doContext(request, ctx);
// 在 GatewayContext 上执行过滤器链逻辑。
filterFactory.buildFilterChain(gatewayContext).doFilter(gatewayContext);
} catch (BaseException e) {
// 通过记录日志并发送适当的 HTTP 响应处理已知异常。
log.error("处理错误 {} {}", e.getCode().getCode(), e.getCode().getMessage());
FullHttpResponse httpResponse = ResponseHelper.getHttpResponse(e.getCode());
doWriteAndRelease(ctx, request, httpResponse);
} catch (Throwable t) {
// 通过记录日志并发送内部服务器错误响应处理未知异常。
log.error("处理未知错误", t);
FullHttpResponse httpResponse = ResponseHelper.getHttpResponse(ResponseCode.INTERNAL_ERROR);
doWriteAndRelease(ctx, request, httpResponse);
}
}
```
可以发现,请求在走到这里的时候,其实接下来就即将开始我的正式对请求的处理过程了,也就是保存并填充我的网关请求上下文,也就是这里的GatewayContext,这个类中包含了当前请求所需要使用的规则,请求体与响应体。保存这个信息是为了接下来后续方便我对请求的不同规则有不同的处理。
不过我并没有在这里就打算马上开始讲解对请求的过滤器链的处理,因为这一节我将侧重在Netty这一块的设计。
那么接下来我们来看Netty对于网络连接这一块的处理吧。
## 网络链接管理
代码中已经比较详细的讲解了这个类的作用。它负责对我们网络请求链接的生命周期进行处理。
这个类对于我们的设计并不是最重要的,所以这里我选择一笔带过这个类。自行查看代码并且进行Debug了解一下什么时候会执行这个类中的方法即可。
比如第一次发送请求创建链接的时候就会调用register和active方法。
```java
package blossom.project.core.netty;
import blossom.project.common.utils.RemotingHelper;
import io.netty.channel.ChannelDuplexHandler;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.timeout.IdleState;
import io.netty.handler.timeout.IdleStateEvent;
import lombok.extern.slf4j.Slf4j;
/**
* 连接管理器,管理连接对生命周期
* 当前类提供出站和入站事件的处理能力,能够管理网络链接的整个生命周期
* 服务器连接管理器,用于监控和管理网络连接的生命周期事件。
*/
@Slf4j
public class NettyServerConnectManagerHandler extends ChannelDuplexHandler {
/**
* 当通道被注册到它的EventLoop时调用,即它可以开始处理I/O事件。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
*/
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
// 获取远程客户端的地址
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
// 记录调试信息
log.debug("NETTY SERVER PIPLINE: channelRegistered {}", remoteAddr);
// 调用父类方法继续处理注册事件
super.channelRegistered(ctx);
}
/**
* 当通道从它的EventLoop注销时调用,不再处理任何I/O事件。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
*/
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception {
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
log.debug("NETTY SERVER PIPLINE: channelUnregistered {}", remoteAddr);
super.channelUnregistered(ctx);
}
/**
* 当通道变为活跃状态,即连接到远程节点时被调用。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
*/
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
log.debug("NETTY SERVER PIPLINE: channelActive {}", remoteAddr);
super.channelActive(ctx);
}
/**
* 当通道变为不活跃状态,即不再连接远程节点时被调用。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
*/
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
log.debug("NETTY SERVER PIPLINE: channelInactive {}", remoteAddr);
super.channelInactive(ctx);
}
/**
* 当用户自定义事件被触发时调用,例如,可以用来处理空闲状态检测事件。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
* @param evt 触发的用户事件。
*/
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
// 检查事件是否为IdleStateEvent(空闲状态事件)
if (evt instanceof IdleStateEvent) {
IdleStateEvent event = (IdleStateEvent) evt;
// 如果是所有类型的空闲事件,则关闭通道
if (event.state().equals(IdleState.ALL_IDLE)) {
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
log.warn("NETTY SERVER PIPLINE: userEventTriggered: IDLE {}", remoteAddr);
ctx.channel().close();
}
}
// 传递事件给下一个ChannelHandler
ctx.fireUserEventTriggered(evt);
}
/**
* 当处理过程中发生异常时调用,通常是网络层面的异常。
*
* @param ctx 提供了操作网络通道的方法的上下文对象。
* @param cause 异常对象。
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
final String remoteAddr = RemotingHelper.parseChannelRemoteAddr(ctx.channel());
// 记录警告信息和异常堆栈
log.warn("NETTY SERVER PIPLINE: remoteAddr: {}, exceptionCaught {}", remoteAddr, cause);
// 发生异常时关闭通道
ctx.channel().close();
}
}
```
## 客户端实现
由于前面我已经在服务端实现的时候列举了所需要的一些关键的组件,而客户端的实现所需要用到的也差不多,所以就不在重复罗列。
这里我讲解一下实现一个异步的HTTP通信客户端如何去实现,这里我用到的是 `AsyncHttpClient` 这样的高层库,它基于Netty构建,提供了异步的HTTP客户端功能,它可以非阻塞地发送HTTP请求,并且能够高效地处理HTTP响应。
讲解了这些,我们再来分析我们的代码就会比较容易理解了:
```java
package blossom.project.core.netty;
import blossom.project.core.Config;
import blossom.project.core.LifeCycle;
import blossom.project.core.helper.AsyncHttpHelper;
import io.netty.buffer.PooledByteBufAllocator;
import io.netty.channel.EventLoopGroup;
import lombok.extern.slf4j.Slf4j;
import org.asynchttpclient.AsyncHttpClient;
import org.asynchttpclient.DefaultAsyncHttpClient;
import org.asynchttpclient.DefaultAsyncHttpClientConfig;
import java.io.IOException;
/**
*
* NettyHttpClient 类负责创建和管理基于Netty的异步HTTP客户端。
* 它实现了LifeCycle接口,以提供初始化、启动和关闭客户端的方法。
*/
@Slf4j
public class NettyHttpClient implements LifeCycle {
// 配置信息对象,包含HTTP客户端的配置参数
private final Config config;
// Netty的事件循环组,用于处理客户端的网络事件
private final EventLoopGroup eventLoopGroupWoker;
// 异步HTTP客户端实例
private AsyncHttpClient asyncHttpClient;
/**
* 构造函数,创建NettyHttpClient的实例。
*
* @param config 包含客户端配置的对象。
* @param eventLoopGroupWoker 用于客户端事件处理的Netty事件循环组。
*/
public NettyHttpClient(Config config, EventLoopGroup eventLoopGroupWoker) {
this.config = config;
this.eventLoopGroupWoker = eventLoopGroupWoker;
init(); // 初始化客户端
}
/**
* 初始化异步HTTP客户端,设置其配置参数。
*/
@Override
public void init() {
// 创建异步HTTP客户端配置的构建器
DefaultAsyncHttpClientConfig.Builder builder = new DefaultAsyncHttpClientConfig.Builder()
.setEventLoopGroup(eventLoopGroupWoker) // 使用传入的Netty事件循环组
.setConnectTimeout(config.getHttpConnectTimeout()) // 连接超时设置
.setRequestTimeout(config.getHttpRequestTimeout()) // 请求超时设置
.setMaxRedirects(config.getHttpMaxRequestRetry()) // 最大重定向次数
.setAllocator(PooledByteBufAllocator.DEFAULT) // 使用池化的ByteBuf分配器以提升性能
.setCompressionEnforced(true) // 强制压缩
.setMaxConnections(config.getHttpMaxConnections()) // 最大连接数
.setMaxConnectionsPerHost(config.getHttpConnectionsPerHost()) // 每个主机的最大连接数
.setPooledConnectionIdleTimeout(config.getHttpPooledConnectionIdleTimeout()); // 连接池中空闲连接的超时时间
// 根据配置创建异步HTTP客户端
this.asyncHttpClient = new DefaultAsyncHttpClient(builder.build());
}
/**
* 启动客户端,通常在这里进行资源分配和启动必要的服务。
*/
@Override
public void start() {
// 使用AsyncHttpHelper单例模式初始化异步HTTP客户端
AsyncHttpHelper.getInstance().initialized(asyncHttpClient);
}
/**
* 关闭客户端,通常在这里进行资源释放和清理工作。
*/
@Override
public void shutdown() {
// 如果客户端实例不为空,则尝试关闭它
if (asyncHttpClient != null) {
try {
// 关闭客户端,并处理可能的异常
this.asyncHttpClient.close();
} catch (IOException e) {
// 记录关闭时发生的错误
log.error("NettyHttpClient shutdown error", e);
}
}
}
}
```
我的客户端就是基于AsyncHttpClient这样子的高层库实现的异步数据交互。
其实到此,对于Netty这一块的设计基本就已经简述了,讲述的比较简单,但是我想可以帮助你顺利的去理解如何基于Netty实现一个网络通信。
# 容器构造
目前我们已经实现了对于当前项目最重要的一个模块,也就是网络通信模块,而我们的网关项目的所有操作其实都依赖于基于Netty实现的模块。
所以我又实现了一个Container容器用于管理管控Netty的模块,负责管控其生命周期。
```
@Slf4j
public class Container implements LifeCycle {
private final Config config;
private NettyHttpServer nettyHttpServer;
private NettyHttpClient nettyHttpClient;
private NettyProcessor nettyProcessor;
public Container(Config config) {
this.config = config;
init();
}
@Override
public void init() {
NettyCoreProcessor nettyCoreProcessor = new NettyCoreProcessor();
//如果启动要使用多生产者多消费组 那么我们读取配置
if (BUFFER_TYPE_PARALLEL.equals(config.getDefaultBufferType())) {
//开启配置的情况下使用Disruptor
this.nettyProcessor = new DisruptorNettyCoreProcessor(config, nettyCoreProcessor);
} else {
this.nettyProcessor = nettyCoreProcessor;
}
this.nettyHttpServer = new NettyHttpServer(config, nettyProcessor);
this.nettyHttpClient = new NettyHttpClient(config,
nettyHttpServer.getEventLoopGroupWoker());
}
@Override
public void start() {
nettyProcessor.start();
nettyHttpServer.start();
;
nettyHttpClient.start();
log.info("api gateway started!");
}
@Override
public void shutdown() {
nettyProcessor.shutDown();
nettyHttpServer.shutdown();
nettyHttpClient.shutdown();
}
}
```
代码依旧比较容易理解,其实就是将之前基于Netty实现的处理类封装到容器中,由容器进行统一管控。
```
//启动容器
Container container = new Container(config);
container.start();
```
之后我们只需要启动容器,我们的基于Netty搭建的网络通信框架就运行起来了,再此时就已经可以接收我们的网络处理请求了。
# 整合Nacos---服务注册与服务订阅的实现
## 什么是Nacos?
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它是阿里巴巴开源的一个项目,专门用于微服务架构的服务治理。Nacos帮助实现了微服务架构中的服务自动发现、服务配置管理、服务元数据及流量管理等核心功能。以下是Nacos的一些主要功能:
1. **服务发现和服务健康监测**:Nacos支持基于DNS或HTTP的服务发现机制,能够实现云端服务的自动注册与发现。它还提供服务健康监测,确保请求仅被发送到健康的主机。
2. **动态配置服务**:动态管理所有服务的配置信息,支持配置自动更新,减少了服务配置变更带来的管理工作与更新延迟。
3. **动态DNS服务**:利用DNS服务,管理云服务的域名解析,实现服务的动态路由和负载均衡。
4. **服务及其元数据管理**:Nacos能够管理服务的元数据信息,如权重、区域、版本等,为服务路由、负载均衡提供依据。
5. **支持AP和CP模式的服务**:根据CAP理论,Nacos支持在AP(可用性和分区容错性)和CP(一致性和分区容错性)模式之间的切换,以满足不同场景的需求。
简而言之,作为目前最火热的注册中心和配置中心,Nacos提供了许多强大的功能,无论是可视化的Web网页方便操作,还是说开箱即用的特性,开源的代码和活跃的社区,以及CP和AP双支持的特性,都是我选择Nacos作为我项目注册中心和配置中心的原因。
## 几个重要概念
在讲解Nacos服务注册的具体代码之前,我们先简单的了解一下Nacos中的几个重要的概念。
1. **服务(Service)**:在Nacos中,服务是指一个或多个相同功能的实例集合,服务通常对应于一个微服务或一个应用。
2. **服务实例(Instance)**:服务实例是指运行服务的最小单位,通常是一个服务的单个运行节点。
3. **配置管理(Configuration Management)**:配置管理允许您集中存储和管理在分布式系统环境中使用的所有配置。
4. **服务注册(Service Registry)**:服务注册是指服务实例启动时,将自己的网络地址(如IP+Port)注册到Nacos中的过程。
5. **服务发现(Service Discovery)**:服务发现是指消费者从Nacos获取服务实例信息的过程,以便进行网络调用。
6. **命名空间(Namespace)**:用于实现环境隔离,不同的命名空间下可以有相同名称的服务。
7. **数据持久化**:Nacos支持数据的持久化存储,它可以将服务信息和配置信息持久化到外部存储(如MySQL数据库)中。
8. **分组(Group)**:用于进一步进行环境隔离。
## 如何将服务注册到Nacos?
上面说了那么多Nacos的优点,接下来就是分析,如何才能将我们的服务注册到Nacos上呢?
**添加Nacos客户端依赖**:在项目的**pom.xml**文件中,添加Nacos客户端的依赖。
```
com.alibaba.nacos
nacos-client
2.0.4
org.slf4j
slf4j-api
1.7.25
org.slf4j
slf4j-simple
1.7.25
```
之后,为了增加通用性以及为了后续方便修改,我们将和注册中心有关的服务抽取到一个接口中:
```java
public interface RegisterCenter {
/**
* 初始化
* @param registerAddress 注册中心地址
* @param env 要注册到的环境
*/
void init(String registerAddress, String env);
/**
* 注册
* @param serviceDefinition 服务定义信息
* @param serviceInstance 服务实例信息
*/
void register(ServiceDefinition serviceDefinition, ServiceInstance serviceInstance);
/**
* 注销
* @param serviceDefinition
* @param serviceInstance
*/
void deregister(ServiceDefinition serviceDefinition, ServiceInstance serviceInstance);
/**
* 订阅所有服务变更
* @param registerCenterListener
*/
void subscribeAllServices(RegisterCenterListener registerCenterListener);
}
```
同时,由于注册中心中注册的服务实例可能发生变化,所以我们还需要提供一个注册中心的监听器来监听注册中心配置的变更。
```
public interface RegisterCenterListener {
void onChange(ServiceDefinition serviceDefinition,
Set serviceInstanceSet);
}
```
整合完毕之后,我们就可以开始考虑如何基于Nacos-Client提供的各类服务来将我们的服务注册到注册中心了。
首先我先贴出Nacos继承的将当前服务注册到服务中心的测试代码:
```java
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.pojo.Instance;
public class NacosRegisterDemo {
public static void main(String[] args) {
try {
// 设置Nacos地址
String serverAddr = "127.0.0.1:8848";
// 创建命名服务实例,用于服务注册
NamingService namingService = NacosFactory.createNamingService(serverAddr);
// 创建服务实例
Instance instance = new Instance();
instance.setIp("你的服务IP"); // 服务实例IP
instance.setPort(你的服务端口); // 服务实例端口
instance.setServiceName("你的服务名称"); // 服务名称
instance.setClusterName("你的服务集群名"); // 服务所在集群
// 添加其他元数据
instance.addMetadata("version", "1.0");
instance.addMetadata("env", "production");
// 注册服务
namingService.registerInstance("你的服务名称", instance);
System.out.println("服务注册成功");
} catch (NacosException e) {
// 异常处理
e.printStackTrace();
}
}
}
```
可以发现其实想要将我们的服务的信息注册到注册中心是非常容易的。
只需要基于我们的NamingService即可,然后调用registerInstance方法将我们设定好的服务实例信息注册上去即可。
那么有了上面的基础知识,再来看看我写的代码:
```
package blossom.project.register.center.nacos.impl;
import blossom.project.common.config.ServiceDefinition;
import blossom.project.common.config.ServiceInstance;
import blossom.project.common.constant.GatewayConst;
import blossom.project.register.center.api.RegisterCenter;
import blossom.project.register.center.api.RegisterCenterListener;
import com.alibaba.fastjson.JSON;
import com.alibaba.nacos.api.exception.NacosException;
import com.alibaba.nacos.api.naming.NamingFactory;
import com.alibaba.nacos.api.naming.NamingMaintainFactory;
import com.alibaba.nacos.api.naming.NamingMaintainService;
import com.alibaba.nacos.api.naming.NamingService;
import com.alibaba.nacos.api.naming.listener.Event;
import com.alibaba.nacos.api.naming.listener.EventListener;
import com.alibaba.nacos.api.naming.listener.NamingEvent;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.alibaba.nacos.api.naming.pojo.Service;
import com.alibaba.nacos.api.naming.pojo.ServiceInfo;
import com.alibaba.nacos.common.executor.NameThreadFactory;
import com.alibaba.nacos.common.utils.CollectionUtils;
import lombok.extern.slf4j.Slf4j;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
/**
* 这个类就用来实现我们注册中心的具体方法
*/
@Slf4j
public class NacosRegisterCenter implements RegisterCenter {
/**
* 注册中心的地址
*/
private String registerAddress;
/**
* 环境选择
*/
private String env;
/**
* 主要用于维护服务实例信息
*/
private NamingService namingService;
/**
* 主要用于维护服务定义信息
*/
private NamingMaintainService namingMaintainService;
/**
* 监听器列表
* 这里由于监听器可能变更 会出现线程安全问题
*/
private List registerCenterListenerList = new CopyOnWriteArrayList<>();
@Override
public void init(String registerAddress, String env) {
this.registerAddress = registerAddress;
this.env = env;
try {
this.namingMaintainService = NamingMaintainFactory.createMaintainService(registerAddress);
this.namingService = NamingFactory.createNamingService(registerAddress);
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
@Override
public void register(ServiceDefinition serviceDefinition, ServiceInstance serviceInstance) {
try {
//构造nacos实例信息
Instance nacosInstance = new Instance();
nacosInstance.setInstanceId(serviceInstance.getServiceInstanceId());
nacosInstance.setPort(serviceInstance.getPort());
nacosInstance.setIp(serviceInstance.getIp());
//实例信息可以放入到metadata中
nacosInstance.setMetadata(Map.of(GatewayConst.META_DATA_KEY, JSON.toJSONString(serviceInstance)));
//注册
namingService.registerInstance(serviceDefinition.getServiceId(), env, nacosInstance);
//更新服务定义
namingMaintainService.updateService(serviceDefinition.getServiceId(), env, 0,
Map.of(GatewayConst.META_DATA_KEY, JSON.toJSONString(serviceDefinition)));
log.info("register {} {}", serviceDefinition, serviceInstance);
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
@Override
public void deregister(ServiceDefinition serviceDefinition, ServiceInstance serviceInstance) {
try {
//进行服务注销
namingService.deregisterInstance(serviceDefinition.getServiceId(), env, serviceInstance.getIp(),
serviceInstance.getPort());
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
@Override
public void subscribeAllServices(RegisterCenterListener registerCenterListener) {
//服务订阅首先需要将我们的监听器加入到我们的服务列表中
registerCenterListenerList.add(registerCenterListener);
//进行服务订阅
doSubscribeAllServices();
//可能有新服务加入,所以需要有一个定时任务来检查
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1, new NameThreadFactory(
"doSubscribeAllServices"));
//循环执行服务发现与订阅操作
scheduledThreadPool.scheduleWithFixedDelay(() -> doSubscribeAllServices(), 10, 10, TimeUnit.SECONDS);
}
private void doSubscribeAllServices() {
try {
//得到当前服务已经订阅的服务
//这里其实已经在init的时候初始化过namingservice了,所以这里可以直接拿到当前服务已经订阅的服务
//如果不了解的可以debug
Set subscribeService =
namingService.getSubscribeServices().stream().map(ServiceInfo::getName).collect(Collectors.toSet());
int pageNo = 1;
int pageSize = 100;
//分页从nacos拿到所有的服务列表
List serviseList = namingService.getServicesOfServer(pageNo, pageSize, env).getData();
//拿到所有的服务名称后进行遍历
while (CollectionUtils.isNotEmpty(serviseList)) {
log.info("service list size {}", serviseList.size());
for (String service : serviseList) {
//判断是否已经订阅了当前服务
if (subscribeService.contains(service)) {
continue;
}
//nacos事件监听器 订阅当前服务
//这里我们需要自己实现一个nacos的事件订阅类 来具体执行订阅执行时的操作
EventListener eventListener = new NacosRegisterListener();
eventListener.onEvent(new NamingEvent(service, null));
namingService.subscribe(service, env, eventListener);
log.info("subscribe {} {}", service, env);
}
//遍历下一页的服务列表
serviseList = namingService.getServicesOfServer(++pageNo, pageSize, env).getData();
}
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
/**
* 实现对nacos事件的监听器 这个事件监听器会在Nacos发生事件变化的时候进行回调
* NamingEvent 是一个事件对象,用于表示与服务命名空间(Naming)相关的事件。
* NamingEvent 的作用是用于监听和处理命名空间中的服务实例(Service Instance)的变化,
* 以便应用程序可以根据这些变化来动态地更新服务实例列表,以保持与注册中心的同步。
*/
public class NacosRegisterListener implements EventListener {
@Override
public void onEvent(Event event) {
//先判断是否是注册中心事件
if (event instanceof NamingEvent) {
log.info("the triggered event info is:{}", JSON.toJSON(event));
NamingEvent namingEvent = (NamingEvent) event;
//获取当前变更的服务名
String serviceName = namingEvent.getServiceName();
try {
//获取服务定义信息
Service service = namingMaintainService.queryService(serviceName, env);
//得到服务定义信息
ServiceDefinition serviceDefinition =
JSON.parseObject(service.getMetadata().get(GatewayConst.META_DATA_KEY),
ServiceDefinition.class);
//获取服务实例信息
List allInstances = namingService.getAllInstances(service.getName(), env);
Set set = new HashSet<>();
/**
* meta-data数据如下
* {
* "version": "1.0.0",
* "environment": "production",
* "weight": 80,
* "region": "us-west",
* "labels": "web, primary",
* "description": "Main production service"
* }
*/
for (Instance instance : allInstances) {
ServiceInstance serviceInstance =
JSON.parseObject(instance.getMetadata().get(GatewayConst.META_DATA_KEY),
ServiceInstance.class);
set.add(serviceInstance);
}
//调用我们自己的订阅监听器
registerCenterListenerList.stream().forEach(l -> l.onChange(serviceDefinition, set));
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
}
}
}
```
代码比较多,我们一个一个来看,NamingService我们已经了解了,这里多了一个namingMaintainService。
**NamingMaintainService** 是 Nacos 客户端提供的一个接口,其作用是维护服务信息,包括服务的更新、查询和删除。它与 **NamingService** 接口不同,后者主要用于服务的注册和发现。
**NamingMaintainService** 提供了更细粒度的控制,允许服务提供者对服务的元数据进行维护,这对于服务的版本控制、区域设置、权重调整等是非常有用的。
在使用 **NamingMaintainService** 时,我们可以执行以下操作:
- **更新服务信息**:可以更新一个服务的元数据,这包括服务的保护阈值、元数据等。
- **查询服务信息**:可以查询服务的当前配置状态,以便进行审查或者其他操作。
- **删除服务信息**:如果一个服务不再需要在注册中心注册,可以使用 **NamingMaintainService** 将其删除。
在我的代码中,**NamingMaintainService** 被用于更新服务定义信息,即当服务定义发生变更时,可以使用这个服务来推送新的服务定义到 Nacos,从而使得注册中心的服务列表保持最新状态。
因此,register方法我们就不多说了,比较好理解,同理deregister方法也比较好理解。
我们按照顺序先来讲解**subscribeAllServices**方法。
顾名思义,这是一个订阅方法。**subscribeAllServices**方法的作用是在Nacos客户端订阅所有服务的变化事件。这是微服务架构中的一个常见需求,因为服务实例可能会动态地上线或下线,服务列表可能会频繁变化。这个方法允许客户端保持对服务状态的最新视图,并且可以在服务变化时做出响应。以下是该方法的详细工作流程和作用:
1. **添加监听器到本地列表**:
- 将参数中的**registerCenterListener**添加到**registerCenterListenerList**中,这个列表维护了所有的监听器,这些监听器将对Nacos服务中心的变化做出响应。
2. **执行服务订阅逻辑**:
- 通过调用**doSubscribeAllServices**方法来执行实际的服务订阅逻辑。
3. **定时任务检查服务变更**:
- 创建一个定时执行的线程池**scheduledThreadPool**,这个线程池负责周期性地调用**doSubscribeAllServices**方法。
- 使用**scheduleWithFixedDelay**方法设置定时任务,每隔一定时间(在这里是10秒)就重新执行**doSubscribeAllServices**方法,以此来检查新的服务是否已经添加或现有服务的状态是否有变更。
4. **处理服务订阅更新**:
- **doSubscribeAllServices**方法将检查Nacos服务列表与当前已订阅服务的差异,并订阅任何新的服务。
- 如果发现新服务,则会创建一个新的**EventListener**,并用它订阅这个服务的变化。一旦服务状态有变化,就会触发事件,然后通过**NamingEvent**事件传递给所有监听器。
5. **事件监听与变更通知**:
- 在**NacosRegisterListener**内部类中定义的**onEvent**方法会在每个服务变化时被调用。
- 当**onEvent**方法被触发时,它会从Nacos服务中心查询服务的当前定义和实例信息,并通知所有注册的**RegisterCenterListener**监听器,这样客户端就可以采取相应的动作,如更新其内部服务列表、重新负载均衡等。
这么多的代码中,也包含了对服务订阅的代码,但是我们先不进行讲解,我们先主要进行对服务注册的代码理解。
```
//连接注册中心,将注册中心的实例加载到本地
final RegisterCenter registerCenter = registerAndSubscribe(config);
private static RegisterCenter registerAndSubscribe(Config config) {
ServiceLoader serviceLoader = ServiceLoader.load(RegisterCenter.class);
final RegisterCenter registerCenter = serviceLoader.findFirst().orElseThrow(() -> {
log.error("not found RegisterCenter impl");
return new RuntimeException("not found RegisterCenter impl");
});
registerCenter.init(config.getRegistryAddress(), config.getEnv());
//构造网关服务定义和服务实例
ServiceDefinition serviceDefinition = buildGatewayServiceDefinition(config);
ServiceInstance serviceInstance = buildGatewayServiceInstance(config);
//注册
registerCenter.register(serviceDefinition, serviceInstance);
//订阅
registerCenter.subscribeAllServices(new RegisterCenterListener() {
@Override
public void onChange(ServiceDefinition serviceDefinition, Set serviceInstanceSet) {
log.info("refresh service and instance: {} {}", serviceDefinition.getUniqueId(),
JSON.toJSON(serviceInstanceSet));
DynamicConfigManager manager = DynamicConfigManager.getInstance();
//将这次变更事件影响之后的服务实例再次添加到对应的服务实例集合
manager.addServiceInstance(serviceDefinition.getUniqueId(), serviceInstanceSet);
//修改发生对应的服务定义
manager.putServiceDefinition(serviceDefinition.getUniqueId(),serviceDefinition);
}
});
return registerCenter;
}
private static ServiceInstance buildGatewayServiceInstance(Config config) {
String localIp = NetUtils.getLocalIp();
int port = config.getPort();
ServiceInstance serviceInstance = new ServiceInstance();
serviceInstance.setServiceInstanceId(localIp + COLON_SEPARATOR + port);
serviceInstance.setIp(localIp);
serviceInstance.setPort(port);
serviceInstance.setRegisterTime(TimeUtil.currentTimeMillis());
return serviceInstance;
}
private static ServiceDefinition buildGatewayServiceDefinition(Config config) {
ServiceDefinition serviceDefinition = new ServiceDefinition();
serviceDefinition.setInvokerMap(Map.of());
serviceDefinition.setUniqueId(config.getApplicationName());
serviceDefinition.setServiceId(config.getApplicationName());
serviceDefinition.setEnvType(config.getEnv());
return serviceDefinition;
}
```
查看上面的代码可以发现,我们的服务注册其实实现比较简单,就是封装服务定义信息和当前服务的服务实例信息,然后调用Nacos提供的服务注册方法来将当前服务的信息注册到注册中心。
同时,我们还在服务注册的时候对当前服务增加了一个服务订阅的机制来监听之后的服务信息变更的事件。
## 如何实现服务订阅?
在上面的章节中我们已经顺带的讲解了服务订阅的一个方式。
这里我将会更加具体的分析服务订阅和服务变更的监听的实现思路。
我们先需要明确一个概念就是,对于注册中心的服务,我们不单单需要对他们进行服务拉取,还需要订阅注册中心中的服务变更的事件。也就是当注册中心中出现了服务变更,我们也是需要配置监听器去处理对应的变更事件的。
因此,当我们的网关服务启动之后,我们就需要将我们当前的服务信息注册到注册中心,同时监听订阅注册中心的配置变更事件。
```
//注册
registerCenter.register(serviceDefinition, serviceInstance);
//订阅
registerCenter.subscribeAllServices(new RegisterCenterListener() {
@Override
public void onChange(ServiceDefinition serviceDefinition, Set serviceInstanceSet) {
log.info("refresh service and instance: {} {}", serviceDefinition.getUniqueId(),
JSON.toJSON(serviceInstanceSet));
DynamicConfigManager manager = DynamicConfigManager.getInstance();
//将这次变更事件影响之后的服务实例再次添加到对应的服务实例集合
manager.addServiceInstance(serviceDefinition.getUniqueId(), serviceInstanceSet);
//修改发生对应的服务定义
manager.putServiceDefinition(serviceDefinition.getUniqueId(),serviceDefinition);
}
});
public void addServiceInstance(String uniqueId, Set serviceInstanceSet) {
serviceInstanceMap.put(uniqueId, serviceInstanceSet);
}
public void putServiceDefinition(String uniqueId,
ServiceDefinition serviceDefinition) {
serviceDefinitionMap.put(uniqueId, serviceDefinition);;
}
```
注册流程比较简单,上文已经讲解,这里我们主要分析订阅事件。
我们会调用我自己实现的注册中心实现类来调用订阅接口,并且传入一个监听器,并且实现这个监听器的onChange方法,这个方法的作用就是当注册中心发生变更事件之后,执行的具体代码操作。
这个方法所执行的内容就是重新加载一次服务实例,确保当前服务实例信息是最新的。同时再一次执行服务定义信息修改方法,修改当前发生变更的服务实例信息。
```
private void doSubscribeAllServices() {
try {
//得到当前服务已经订阅的服务
//这里其实已经在init的时候初始化过namingservice了,所以这里可以直接拿到当前服务已经订阅的服务
//如果不了解的可以debug
Set subscribeServiceSet =
namingService.getSubscribeServices().stream().map(ServiceInfo::getName).collect(Collectors.toSet());
int pageNo = 1;
int pageSize = 100;
//分页从nacos拿到所有的服务列表
List serviseList = namingService.getServicesOfServer(pageNo, pageSize, env).getData();
//拿到所有的服务名称后进行遍历
while (CollectionUtils.isNotEmpty(serviseList)) {
log.info("service list size {}", serviseList.size());
for (String service : serviseList) {
//判断是否已经订阅了当前服务
if (subscribeServiceSet.contains(service)) {
continue;
}
//nacos事件监听器 订阅当前服务
//这里我们需要自己实现一个nacos的事件订阅类 来具体执行订阅执行时的操作
EventListener eventListener = new NacosRegisterListener();
//当前服务之前不存在 调用监听器方法进行添加处理
eventListener.onEvent(new NamingEvent(service, null));
//为指定的服务和环境注册一个事件监听器
namingService.subscribe(service, env, eventListener);
log.info("subscribe a service ,ServiceName {} Env {}", service, env);
}
//遍历下一页的服务列表
serviseList = namingService.getServicesOfServer(++pageNo, pageSize, env).getData();
}
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
/**
* 实现对nacos事件的监听器 这个事件监听器会在Nacos发生事件变化的时候进行回调
* NamingEvent 是一个事件对象,用于表示与服务命名空间(Naming)相关的事件。
* NamingEvent 的作用是用于监听和处理命名空间中的服务实例(Service Instance)的变化,
* 以便应用程序可以根据这些变化来动态地更新服务实例列表,以保持与注册中心的同步。
*/
public class NacosRegisterListener implements EventListener {
@Override
public void onEvent(Event event) {
//先判断是否是注册中心事件
if (event instanceof NamingEvent) {
log.info("the triggered event info is:{}", JSON.toJSON(event));
NamingEvent namingEvent = (NamingEvent) event;
//获取当前变更的服务名
String serviceName = namingEvent.getServiceName();
try {
//获取服务定义信息
Service service = namingMaintainService.queryService(serviceName, env);
//得到服务定义信息
ServiceDefinition serviceDefinition =
JSON.parseObject(service.getMetadata().get(GatewayConst.META_DATA_KEY),
ServiceDefinition.class);
//获取服务实例信息
List allInstances = namingService.getAllInstances(service.getName(), env);
Set set = new HashSet<>();
/**
* meta-data数据如下
* {
* "version": "1.0.0",
* "environment": "production",
* "weight": 80,
* "region": "us-west",
* "labels": "web, primary",
* "description": "Main production service"
* }
*/
for (Instance instance : allInstances) {
ServiceInstance serviceInstance =
JSON.parseObject(instance.getMetadata().get(GatewayConst.META_DATA_KEY),
ServiceInstance.class);
set.add(serviceInstance);
}
//调用我们自己的订阅监听器
registerCenterListenerList.stream().forEach(registerCenterListener ->
registerCenterListener.onChange(serviceDefinition, set));
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
}
}
```
上面这段代码就是服务订阅和服务变更监听的相关代码。
其作用就是在发生服务变更,比如服务实例的上线或者下线的时候,根据当前发生变更的服务名称,比如当前上线了一个api-user的服务实例,那么就会触发更新操作,然后获取当前服务实例对应的服务,并且根据当前的服务拉取当前服务所对应的存在的所有服务实例,并且进行保存,那么此时我们就得到了更新后的服务实例信息和服务订阅信息了,因为这里的onChange方法会将我们的服务定义和服务实例信息放入到我们一开始设定的DynamicConfigManager中,而它就是我们存储服务实例、服务定义信息的一个管理容器。
下面附上一张服务实例信息的元数据信息来帮助你更好的理解元数据到底是什么样子的。
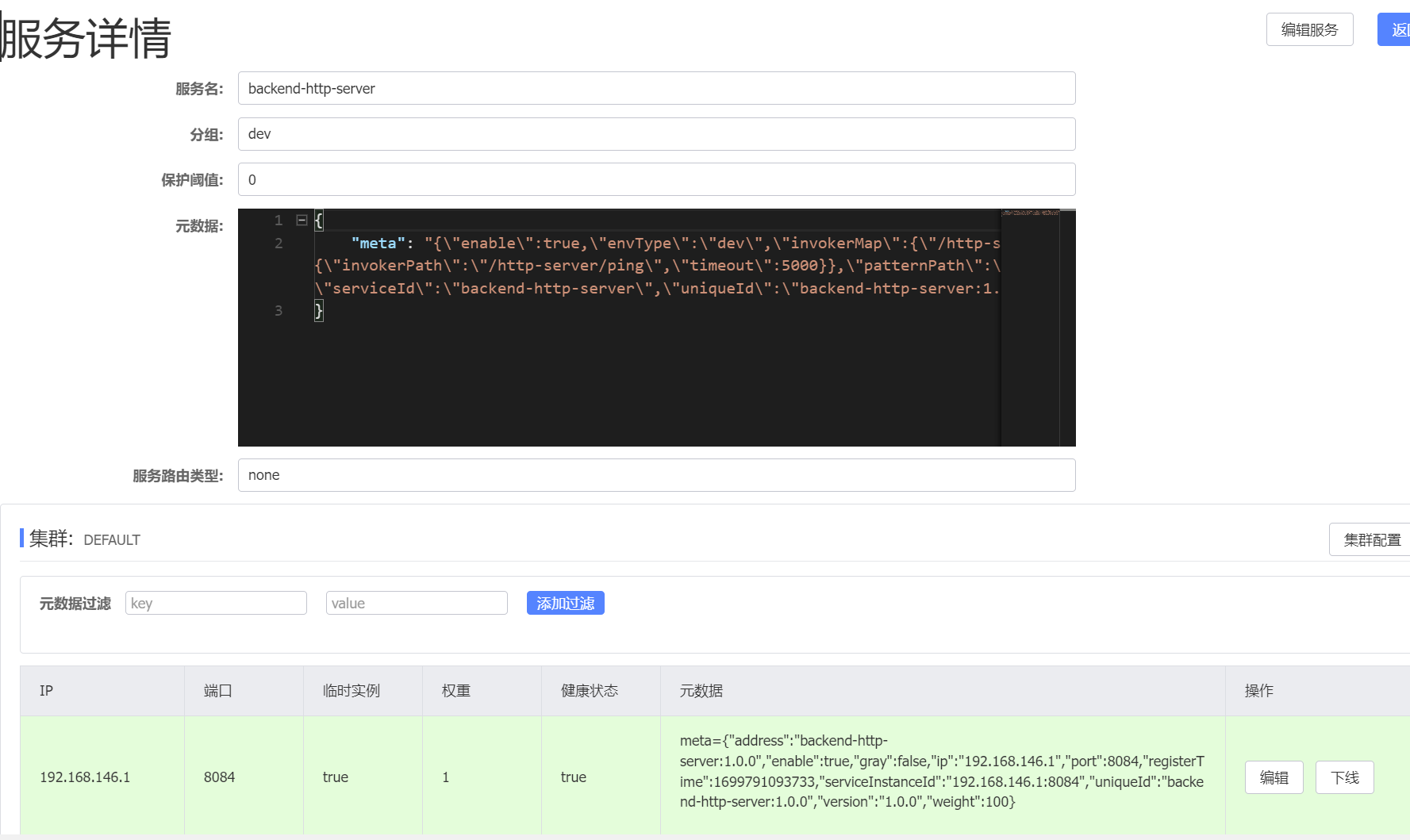
到此,其实我们就已经完成了服务订阅。
其实服务订阅和服务注册的代码都比较通用,只要编写一次之后按照固定的类似的模板去编写代码即可。
# 整合Nacos---使用配置中心与配置变更事件监听
这里我们依旧按照上面的方式来讲解这一节。
我想你一定至少简单了解或者使用过配置中心,在Nacos中,我们可以将我们的配置编写在配置中心中,然后再服务启动的时候主动的拉取配置中心中的代码并且作用在本地,同时当配置中心中的配置发生变更的时候我们也可以根据服务订阅事件得到配置中心中变更的配置信息。

从上图就可以比较容易的了解配置中心的构成,这里就不在赘述。
这里我依旧是写了一套入门的代码来帮助你了解如何从Nacos的配置中心拉取我们的配置。
```
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.config.listener.Listener;
import com.alibaba.nacos.api.exception.NacosException;
import java.util.Properties;
import java.util.concurrent.Executor;
public class NacosConfigDemo {
public static void main(String[] args) throws NacosException, InterruptedException {
String serverAddr = "127.0.0.1:8848"; // Nacos服务器地址
String dataId = "example"; // 配置的Data ID
String group = "DEFAULT_GROUP"; // 配置所在的Group
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
ConfigService configService = NacosFactory.createConfigService(properties);
// 获取配置
String content = configService.getConfig(dataId, group, 5000);
System.out.println(content);
// 监听配置变更
configService.addListener(dataId, group, new Listener() {
@Override
public void receiveConfigInfo(String configInfo) {
System.out.println("配置已更新: " + configInfo);
}
@Override
public Executor getExecutor() {
return null;
}
});
// 保持程序运行,以监听配置变更
while (true) {
Thread.sleep(2000);
}
}
}
```
可以发现和进行服务注册一样,使用配置中心进行配置的拉取以及配置变更的订阅都非常容易,我们先从配置的拉取来实现。
还是老方法,为了增加通用性,我们编写一套对应配置中心的接口。
```
public interface ConfigCenter {
/**
* 初始化配置中心配置
* @param serverAddr 配置中心地址
* @param env 环境
*/
void init(String serverAddr, String env);
/**
* 订阅配置中心配置变更
* @param listener 配置变更监听器
*/
void subscribeRulesChange(RulesChangeListener listener);
}
```
```
public interface RulesChangeListener {
/**
* 规则变更时调用此方法 对规则进行更新
* @param rules 新规则
*/
void onRulesChange(List rules);
}
```
之后我们开始分析如何基于Nacos-Client来实现配置拉取和配置变更订阅。
```
package blossom.project.config.center.nacos.impl;
import blossom.project.common.config.Rule;
import blossom.project.config.center.api.ConfigCenter;
import blossom.project.config.center.api.RulesChangeListener;
import com.alibaba.fastjson.JSON;
import com.alibaba.nacos.api.NacosFactory;
import com.alibaba.nacos.api.config.ConfigService;
import com.alibaba.nacos.api.config.listener.Listener;
import com.alibaba.nacos.api.exception.NacosException;
import lombok.extern.slf4j.Slf4j;
import java.util.List;
import java.util.concurrent.Executor;
/**
* 这个类就用来实现我们配置中心的具体方法
*/
@Slf4j
public class NacosConfigCenter implements ConfigCenter {
/**
* 需要拉取的服务配置的DATA_ID 要求自定义
*/
private static final String DATA_ID = "api-gateway";
/**
* 服务端地址
*/
private String serverAddr;
/**
* 环境
*/
private String env;
/**
* Nacos提供的与配置中心进行交互的接口
*/
private ConfigService configService;
@Override
public void init(String serverAddr, String env) {
this.serverAddr = serverAddr;
this.env = env;
try {
this.configService = NacosFactory.createConfigService(serverAddr);
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
@Override
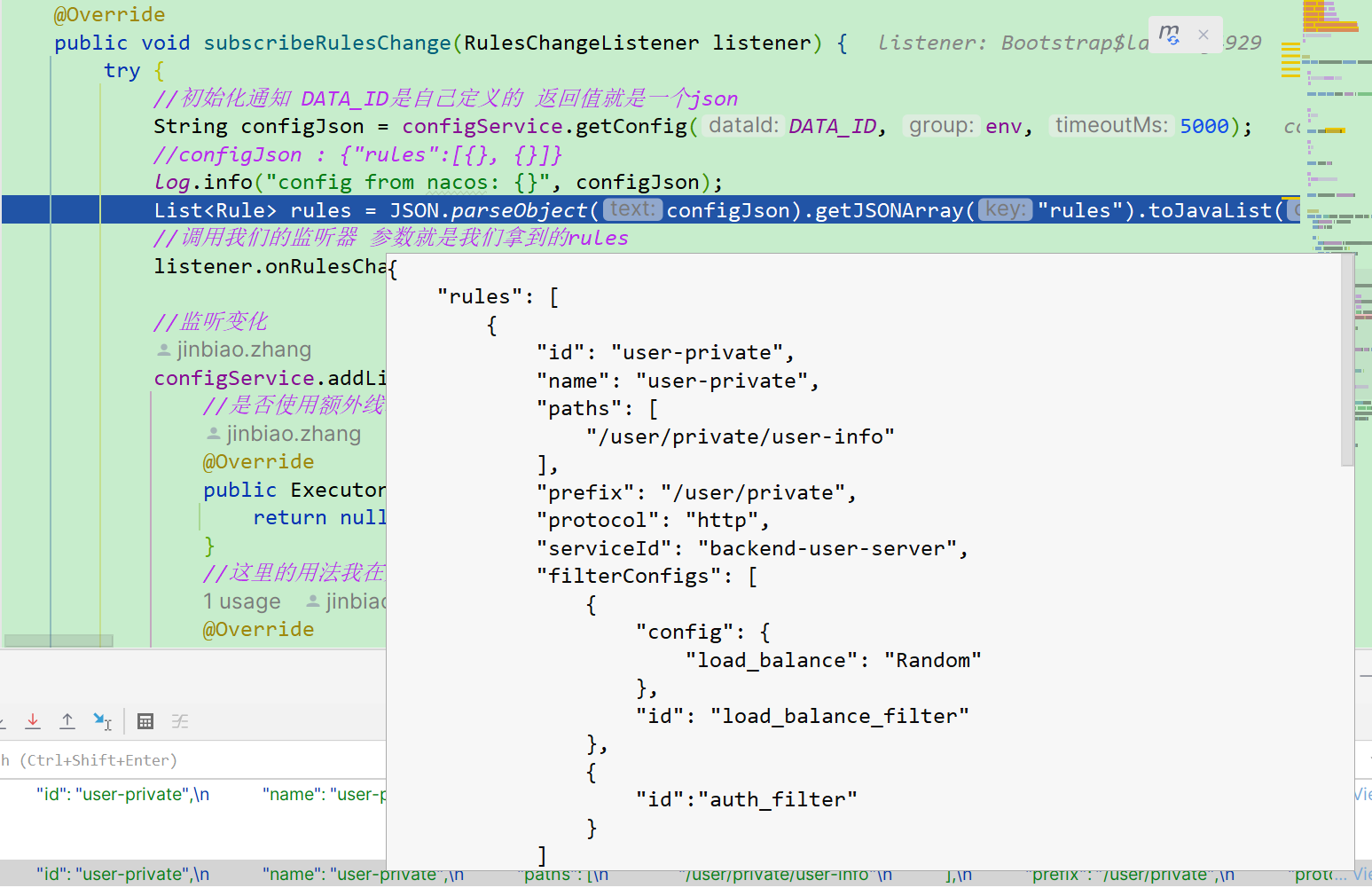
public void subscribeRulesChange(RulesChangeListener listener) {
try {
//初始化通知 DATA_ID是自己定义的 返回值就是一个json
String configJson = configService.getConfig(DATA_ID, env, 5000);
//configJson : {"rules":[{}, {}]}
log.info("config from nacos: {}", configJson);
List rules = JSON.parseObject(configJson).getJSONArray("rules").toJavaList(Rule.class);
//调用我们的监听器 参数就是我们拿到的rules
listener.onRulesChange(rules);
//监听变化
configService.addListener(DATA_ID, env, new Listener() {
//是否使用额外线程执行
@Override
public Executor getExecutor() {
return null;
}
//这里的用法我在那片线程池动态调参的时候写到过,有兴趣可以查看博客
@Override
public void receiveConfigInfo(String configInfo) {
log.info("config from nacos: {}", configInfo);
List rules = JSON.parseObject(configInfo).getJSONArray("rules").toJavaList(Rule.class);
listener.onRulesChange(rules);
}
});
} catch (NacosException e) {
throw new RuntimeException(e);
}
}
}
```
可以发现代码和上面的入门代码差不多,都是直接调用getConfig方法来获取配置,然后对配置进行解析,这里的配置其实就是我们上图中的yaml配置了,由于我们已经知道了我们配置的格式和信息,所以我们可以自定义一个类来进行转化和解析。
在我们的项目首次启动的时候就会调用subscribeRulesChange这个方法来拉取配置,从而初始化我们的过滤器的规则,同时我们也会配置一个监听器来监听我们的配置中心的配置变更事件。
而具体的监听代码再启动类中给出,如下:
```
// 从配置中心获取配置
configCenter.init(config.getRegistryAddress(), config.getEnv());
configCenter.subscribeRulesChange(rules -> DynamicConfigManager.getInstance()
.putAllRule(rules));
```
可以发现,当配置发生变更的时候,我们做的事情其实就是拉取此时的最新配置,然后再次将其解析为Rule对象,然后我们会将这个包含了大量Rule的List集合进行处理,将其放入到DynamicConfigManager。
```
public void putAllRule(List ruleList) {
ConcurrentHashMap newRuleMap = new ConcurrentHashMap<>();
ConcurrentHashMap newPathMap = new ConcurrentHashMap<>();
ConcurrentHashMap> newServiceMap = new ConcurrentHashMap<>();
for(Rule rule : ruleList){
newRuleMap.put(rule.getId(),rule);
List rules = newServiceMap.get(rule.getServiceId());
if(rules == null){
rules = new ArrayList<>();
}
rules.add(rule);
newServiceMap.put(rule.getServiceId(),rules);
List paths = rule.getPaths();
for(String path :paths){
String key = rule.getServiceId()+"."+path;
newPathMap.put(key,rule);
}
}
ruleMap = newRuleMap;
pathRuleMap = newPathMap;
serviceRuleMap = newServiceMap;
}
```
此时我们就基于路径和服务存放了我们的规则,因为我们的规则可能是按照路径生效,也可能按照服务生效。
到此为止,配置中心的配置拉取和配置变更事件的监听我们都已经完成了。
Nacos的部分到此基本结束。
# 网关规则管控
## 规则的加载
在上面的章节中,我们已经实现了包含注册中心配置中心、网络通信框架、容器、配置的所有代码的实现。
接下来我们就要开始真正的处理我们的网络请求部分的代码的设计和实现了。
首先我们都明白,网关中有一个特别核心的概念就是,对于不同的路径,会有不同的正则表达式去匹配,从而对这些路径进行不同的处理。
我称这些表达式为:规则。
也就是在这个模块,我将和你分析如何实现所谓的:规则。
首先我们先定义规则类,确定好我们的规则所需要用到的一些基本信息。
这些配置对应的含义我也已经在代码中进行标注,代码比较简单好理解,就是定义了一些对应的规则会用到的类信息,比如Hystrix和熔断限流会用到的信息,我也为其定义了一个类。
```
package blossom.project.common.config;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.HashSet;
import java.util.List;
import java.util.Objects;
import java.util.Set;
/**
* Rule规则类
*/
@Data
@AllArgsConstructor
@Builder
public class Rule implements Comparable, Serializable {
/**
* 规则ID,全局唯一
*/
private String id;
/**
* 规则名称
*/
private String name;
/**
* 协议
*/
private String protocol;
/**
* 后端服务ID
*/
private String serviceId;
/**
* 请求前缀
*/
private String prefix;
/**
* 路径集合
*/
private List paths;
/**
* 规则排序,对应场景:一个路径对应多条规则,然后只执行一条规则的情况
*/
private Integer order;
/**
* 过滤器配置信息
*/
private Set filterConfigs = new HashSet<>();
/**
* 限流规则
*/
private Set flowControlConfigs = new HashSet<>();
/**
* 重试规则
*/
private RetryConfig retryConfig = new RetryConfig();
/**
* 熔断规则
*/
private Set hystrixConfigs = new HashSet<>();
public Rule() {
super();
}
public Rule(String id, String name, String protocol, String serviceId, String prefix, List paths,
Integer order, Set filterConfigs) {
this.id = id;
this.name = name;
this.protocol = protocol;
this.serviceId = serviceId;
this.prefix = prefix;
this.paths = paths;
this.order = order;
this.filterConfigs = filterConfigs;
}
@Data
public static class FilterConfig {
/**
* 过滤器唯一ID
*/
private String id;
/**
* 过滤器规则描述,{"timeOut":500,"balance":random}
*/
private String config;
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if ((o == null) || getClass() != o.getClass()) {
return false;
}
FilterConfig that = (FilterConfig) o;
return id.equals(that.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
@Data
public static class FlowControlConfig {
/**
* 限流类型-可能是path,也可能是IP或者服务
*/
private String type;
/**
* 限流对象的值
*/
private String value;
/**
* 限流模式-单机还有分布式
*/
private String model;
/**
* 限流规则,是一个JSON
*/
private String config;
}
@Data
public static class RetryConfig {
private int times;
public int getTimes() {
return times;
}
public void setTimes(int times) {
this.times = times;
}
}
@Data
public static class HystrixConfig {
/**
* 熔断降级陆军
*/
private String path;
/**
* 超时时间
*/
private int timeoutInMilliseconds;
/**
* 核心线程数量
*/
private int threadCoreSize;
/**
* 熔断降级响应
*/
private String fallbackResponse;
}
/**
* 向规则里面添加过滤器
*
* @param filterConfig
* @return
*/
public boolean addFilterConfig(FilterConfig filterConfig) {
return filterConfigs.add(filterConfig);
}
/**
* 通过一个指定的FilterID获取FilterConfig
*
* @param id
* @return
*/
public FilterConfig getFilterConfig(String id) {
for (FilterConfig config : filterConfigs) {
if (config.getId().equalsIgnoreCase(id)) {
return config;
}
}
return null;
}
/**
* 根据filterID判断当前Rule是否存在
*
* @return
*/
public boolean hashId(String id) {
for (FilterConfig filterConfig : filterConfigs) {
if (filterConfig.getId().equalsIgnoreCase(id)) {
return true;
}
}
return false;
}
@Override
public int compareTo(Rule o) {
int orderCompare = Integer.compare(getOrder(), o.getOrder());
if (orderCompare == 0) {
return getId().compareTo(o.getId());
}
return orderCompare;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if ((o == null) || getClass() != o.getClass()) {
return false;
}
FilterConfig that = (FilterConfig) o;
return id.equals(that.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
```
之后,每当我们项目启动运行的时候,都会**从配置中心拉取对应的配置**。
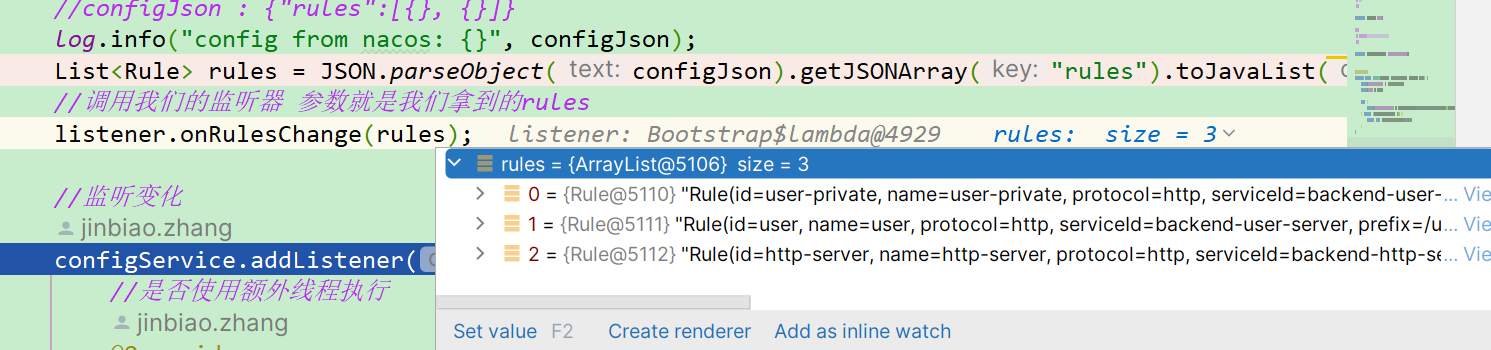
此时,我们对应的配置就已经加载好了,并且当配置中心发生配置变更的时候也会触发配置变更事件从而重新导入加载配置。
到此规则的加载就结束了,我将会在下文提到过滤器的时候通过对规则的配置来使得过滤器有不同的效果。
## 如何存储规则?
规则的加载比较容易,并且我们也看到了规则的编写方法,只需要定义一个类,这个类提供你的规则使用时所需要用到的属性即可。
那么如何去使用规则呢?规则是如何生效的呢?
为了便于理解,我将从规则获取与存放的地方开始,从0为你讲解规则的存放方式。
```
// 从配置中心获取配置
configCenter.init(config.getRegistryAddress(), config.getEnv());
configCenter.subscribeRulesChange(rules -> DynamicConfigManager.getInstance()
.putAllRule(rules));
public void putAllRule(List ruleList) {
ConcurrentHashMap newRuleMap = new ConcurrentHashMap<>();
ConcurrentHashMap newPathMap = new ConcurrentHashMap<>();
ConcurrentHashMap> newServiceMap = new ConcurrentHashMap<>();
for(Rule rule : ruleList){
newRuleMap.put(rule.getId(),rule);
List rules = newServiceMap.get(rule.getServiceId());
if(rules == null){
rules = new ArrayList<>();
}
rules.add(rule);
newServiceMap.put(rule.getServiceId(),rules);
List paths = rule.getPaths();
for(String path :paths){
String key = rule.getServiceId()+"."+path;
newPathMap.put(key,rule);
}
}
ruleMap = newRuleMap;
pathRuleMap = newPathMap;
serviceRuleMap = newServiceMap;
}
```
可以发现,当我们的项目启动的时候,我们就已经从配置中心拉取了配置,也就是规则,此时规则通过JSON的解析,我们就得到了规则集合List。
而这些集合中的规则将会被进一步的处理。
在上文中我提到了,规则分为基于路径的规则和基于服务的规则。并且每一个规则有它的唯一编号防止重复。
其中id就是规则的唯一编号,用于表示我们的规则,name表示规则的名称,paths表示规则将会对那些路径进行生效,prefix表示路径的前缀,protocol表示规则对什么协议生效,serviceId表示当前规则适用于什么服务(名称),filterConfigs就是对我们的过滤器的具体配置信息了,过滤器的部分是我们项目的核心部分,我也会在接下来的章节中具体的进行讲解。
```
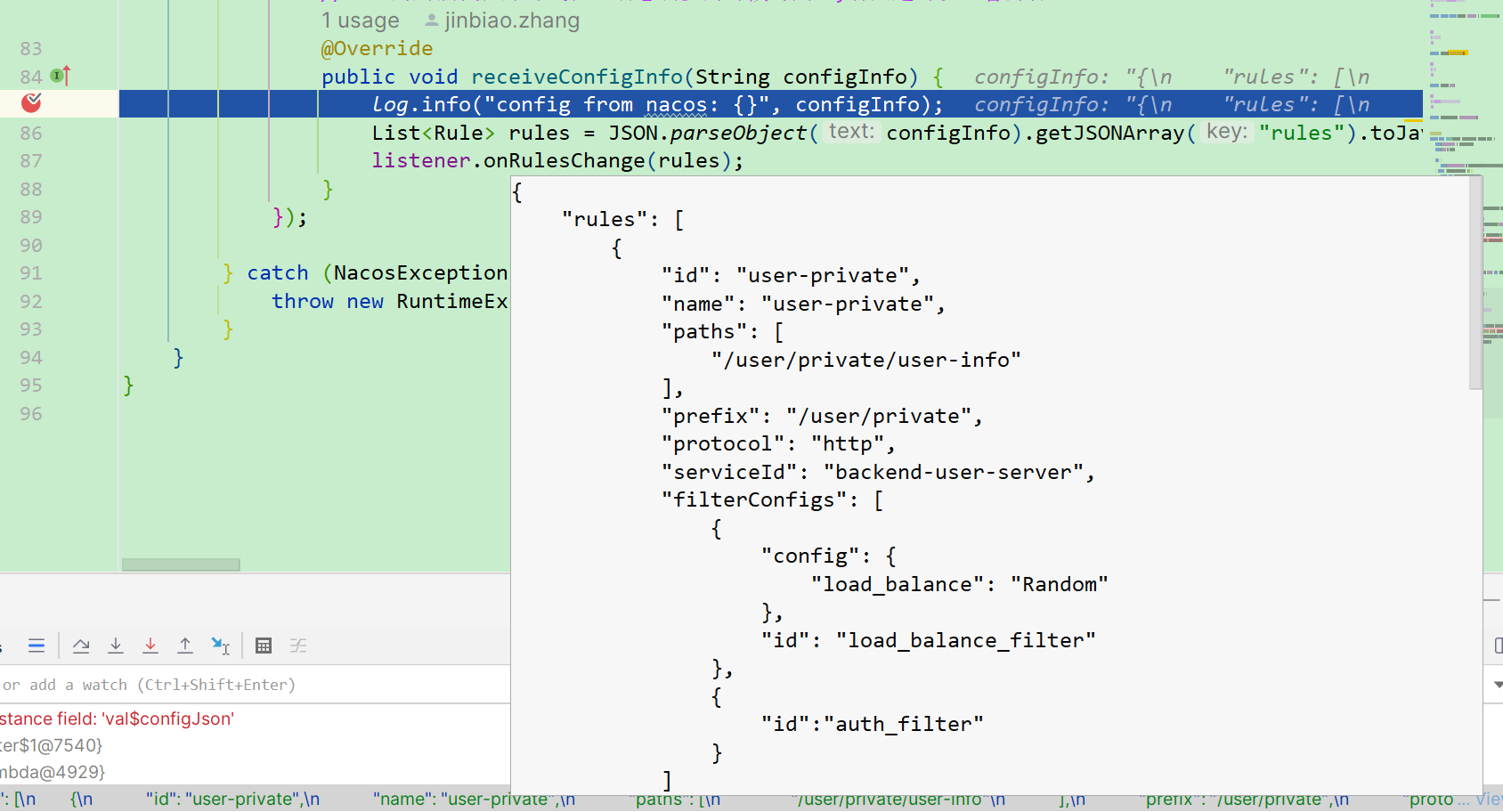
"rules": [
{
"id": "user-private",
"name": "user-private",
"paths": [
"/user/private/user-info"
],
"prefix": "/user/private",
"protocol": "http",
"serviceId": "backend-user-server",
"filterConfigs": [
{
"config": {
"load_balance": "Random"
},
"id": "load_balance_filter"
},
{
"id":"auth_filter"
}
]
}]
```
当我们从配置中心拉取配置并解析完毕之后,我们就开始了规则的存放。
我们首先查看serviceRuleMap,他代表的是对于这些Service服务的规则有那些。

而我们的ruleMap存放的是Map的方式,也就是规则的ID对应规则的信息。
pathRuleMap最好理解,他存放的就是当前路径对应的规则。

这里如果单独只是用请求的路径,那么可能会出现路径重复的问题,因此我自定义了一个规则,按照如下方式来设定我们的key。
```
String key = rule.getServiceId()+"."+path
```
到此为止我们就已经在项目启动之后将我们的各种不同的规则进行了保存。以方便我们在后续需要使用的时候取出进行使用。
那么有了这些前置知识,我们就可以完成对网关请求上下文的封装了。
```
//根据请求对象获取规则
Rule rule = getRule(gateWayRequest, serviceDefinition.getServiceId());
// 构建我们而定GateWayContext对象
GatewayContext gatewayContext = new GatewayContext(serviceDefinition.getProtocol(), ctx,
HttpUtil.isKeepAlive(request), gateWayRequest, rule,0);
/**
* 根据请求对象获取Rule对象
*
* @param gateWayRequest 请求对象
* @return
*/
private static Rule getRule(GatewayRequest gateWayRequest, String serviceId) {
String key = serviceId + "." + gateWayRequest.getPath();
Rule rule = DynamicConfigManager.getInstance().getRuleByPath(key);
if (rule != null) {
return rule;
}
return DynamicConfigManager.getInstance().getRuleByServiceId(serviceId).stream()
.filter(r -> gateWayRequest.getPath().startsWith(r.getPrefix())).findAny()
.orElseThrow(() -> new ResponseException(PATH_NO_MATCHED));
}
```
# 过滤器链的设计
## 过滤器的设计
在设计过滤器链之前,我们先设计出来过滤器的结构。
根据之前的文章,其实我们可以知道,过滤器对请求的处理方式其实就是将我们的网关请求上下文GatewayContext放入到我们的某一个具体的过滤器中然后执行过滤器方法即可。
同时,参考SpringCloudGateway我们知道,过滤器链中的过滤器是有序执行的,因此我们还需要使得当前过滤器提供一个方法来返回其顺序。
那么我们可以设计出过滤器结构如下:
```
public interface Filter {
void doFilter(GatewayContext ctx) throws Exception;
default int getOrder(){
FilterAspect annotation = this.getClass().getAnnotation(FilterAspect.class);
if(annotation != null){
return annotation.order();
}
return Integer.MAX_VALUE;
};
}
```
## 过滤器链工厂
上文中已经提到了,对于每一个请求,我们的处理方式是通过过滤器链的方式来对进行处理,也就是每一个请求都将按照规则走完一套过滤器链流程。
那么接下来我们来分析一下如何设计过滤器链条。
首先从请求接收处开始考虑,我们的每一个请求都需要通过NettyCoreProcessor的处理,这个类中我们将先将我们的请求信息封装为我们的网关上下文信息。
```
// 创建并填充 GatewayContext 以保存有关传入请求的信息。
GatewayContext gatewayContext = RequestHelper.doContext(request, ctx);
// 在 GatewayContext 上执行过滤器链逻辑。
filterFactory.buildFilterChain(gatewayContext).doFilter(gatewayContext);
```
之后我们就可以基于网关上下文信息构建过滤器链,然后开始执行过滤器链中的过滤器方法。
这里之所以要构建过滤器链是因为,我们的每一个不同的请求,每一个携带不同参数的请求,都有可能触发不同的过滤器链规则,因此,我们需要使用过滤器链工厂,为我们的请求信息专门的生成过滤器链去执行请求。当然,这样子的性能会有影响,所以我会在后续对这个地方进行优化。
既然上文提到我们需要对不同的请求构建过滤器链,那么我们就按照工厂方法的方式去实现,提供过滤器链生产方法以及根据过滤器ID获得过滤器的方法即可。
```
public interface FilterChainFactory {
/**
* 构建过滤器链条
* @param ctx
* @return
* @throws Exception
*/
GatewayFilterChain buildFilterChain(GatewayContext ctx) throws Exception;
/**
* 通过过滤器ID获取过滤器
* @param filterId
* @return
* @param
* @throws Exception
*/
T getFilterInfo(String filterId) throws Exception;
}
```
而过滤器链的实现可以按照如下的步骤去实现:
1. 加载所有过滤器
2. 遍历规则,并判断当前路径是否启用当前过滤器
3. 将适用的过滤器添加到集合中
4. 路由过滤器是最后生效的过滤器,上述步骤完成后最后放入路由过滤器
5. 按照过滤器的生效顺序对过滤器进行排序
6. 过滤器链创建成功
所以,按照上面的步骤,并结合我们之前的代码,不难得出如下代码:
```
@Slf4j
public class GatewayFilterChainChainFactory implements FilterChainFactory {
private static class SingletonInstance {
private static final GatewayFilterChainChainFactory INSTANCE = new GatewayFilterChainChainFactory();
}
public static GatewayFilterChainChainFactory getInstance() {
return SingletonInstance.INSTANCE;
}
/**
* 使用Caffeine缓存 并且设定过期时间10min
*/
private Cache chainCache = Caffeine.newBuilder().recordStats().expireAfterWrite(10,
TimeUnit.MINUTES).build();
//过滤器映射
private Map processorFilterIdMap = new ConcurrentHashMap<>();
public GatewayFilterChainChainFactory() {
//加载所有过滤器
ServiceLoader serviceLoader = ServiceLoader.load(Filter.class);
serviceLoader.stream().forEach(filterProvider -> {
Filter filter = filterProvider.get();
FilterAspect annotation = filter.getClass().getAnnotation(FilterAspect.class);
log.info("load filter success:{},{},{},{}", filter.getClass(), annotation.id(), annotation.name(),
annotation.order());
if (annotation != null) {
//添加到过滤集合
String filterId = annotation.id();
if (StringUtils.isEmpty(filterId)) {
filterId = filter.getClass().getName();
}
processorFilterIdMap.put(filterId, filter);
}
});
}
public static void main(String[] args) {
new GatewayFilterChainChainFactory();
}
@Override
public GatewayFilterChain buildFilterChain(GatewayContext ctx) throws Exception {
//return chainCache.get(ctx.getRule().getId(),k->doBuildFilterChain(ctx.getRule()));
return doBuildFilterChain(ctx.getRule());
}
public GatewayFilterChain doBuildFilterChain(Rule rule) {
GatewayFilterChain chain = new GatewayFilterChain();
List filters = new ArrayList<>();
//手动将某些过滤器加入到过滤器链中
filters.add(getFilterInfo(FilterConst.GRAY_FILTER_ID));
filters.add(getFilterInfo(FilterConst.MONITOR_FILTER_ID));
filters.add(getFilterInfo(FilterConst.MONITOR_END_FILTER_ID));
filters.add(getFilterInfo(FilterConst.MOCK_FILTER_ID));
if (rule != null) {
Set filterConfigs = rule.getFilterConfigs();
Iterator iterator = filterConfigs.iterator();
Rule.FilterConfig filterConfig;
while (iterator.hasNext()) {
filterConfig = (Rule.FilterConfig) iterator.next();
if (filterConfig == null) {
continue;
}
String filterId = filterConfig.getId();
if (StringUtils.isNotEmpty(filterId) && getFilterInfo(filterId) != null) {
Filter filter = getFilterInfo(filterId);
filters.add(filter);
}
}
}
//添加路由过滤器-这是最后一步
filters.add(getFilterInfo(FilterConst.ROUTER_FILTER_ID));
//排序
filters.sort(Comparator.comparingInt(Filter::getOrder));
//添加到链表中
chain.addFilterList(filters);
return chain;
}
@Override
public Filter getFilterInfo(String filterId) {
return processorFilterIdMap.get(filterId);
}
}
```
之后,过滤器链工厂方法也已经实现了,最后就是轮到了对过滤器链中过滤器的执行,由于我们知道其实过滤器链就是一个过滤器集合,因此我们可以容易的的得出只需要将网关上下文放入到过滤器中进行执行,并且使用迭代器遍历过滤器让他们去执行过滤方法即可。
```
@Slf4j
public class GatewayFilterChain {
private List filters = new ArrayList<>();
public GatewayFilterChain addFilter(Filter filter){
filters.add(filter);
return this;
}
public GatewayFilterChain addFilterList(List filter){
filters.addAll(filter);
return this;
}
/**
* 执行过滤器处理流程
* @param ctx
* @return
* @throws Exception
*/
public GatewayContext doFilter(GatewayContext ctx) throws Exception {
if(filters.isEmpty()){
return ctx;
}
try {
for(Filter fl: filters){
fl.doFilter(ctx);
if (ctx.isTerminated()){
break;
}
}
}catch (Exception e){
log.error("执行过滤器发生异常,异常信息:{}",e.getMessage());
throw e;
}
return ctx;
}
}
```
到此为止,过滤器链条和过滤器的设计我们都已经完成了。
接下来的章节其实就是基本思考如何对于某一些具体的需求来实现一个具体的过滤器了,比如负载均衡过滤器,路由过滤器,鉴权过滤器等等过滤器。
# 不同过滤器的具体实现
这一章节我们来思考如何基于不同的需求实现不同的过滤器。
参考SpringCloudGateway的实现,不同过滤器一般提供如下的这些功能。
1. **决定路由**:路由过滤器负责确定请求应该被路由到哪个微服务。基于请求的 URL、头信息或其他参数,路由过滤器可以决定合适的服务实例进行处理。
2. **修改请求和响应**:在路由请求到目标服务之前,路由过滤器可以修改请求。这包括添加、删除或修改请求头,改变请求的目的地,或者增加查询参数等。
3. **认证和授权**:虽然通常由专门的过滤器处理,但路由过滤器也可以参与检查用户的认证和授权信息,以决定是否允许请求被路由到下游服务。
4. **负载均衡**:在一个微服务架构中,一个服务可能有多个实例。路由过滤器可以实现负载均衡,确保请求均匀地分布在不同的服务实例上。
5. **容错和重试机制**:路由过滤器可以实现容错机制,比如当目标服务不可用时,自动重试其他实例或提供备用响应。
6. **日志和监控**:在路由请求的过程中,路由过滤器可以记录关于请求的重要信息,这对于监控和分析系统性能至关重要。
7. **处理响应**:在从目标服务接收到响应后,路由过滤器可以对响应进行修改或处理,例如修改响应头、更改响应状态码或者对返回的数据进行转换。
8. **限流和熔断**:在高流量场景中,路由过滤器可以实现限流策略来防止系统过载,或者在后端服务故障时提供熔断机制。
而我的网关项目也将提供这些最基本的过滤器功能。
我的网关中包含:鉴权、限流、熔断、负载均衡、Mock、监控、路由七大过滤器。
其中,最最基础的过滤器其实就是我们的路由过滤器和负载均衡过滤器了。
这里我选择先讲解负载均衡过滤器,之后讲解路由过滤器。
并且接下来对每一个过滤器的实现的讲解,我都会按照设计思路,代码实现两步走的方式来讲解。
## 负载均衡过滤器
**设计思路:**
我们知道,负载均衡其实就是按照一定的策略,从多个的后端服务实例中选取一个实例,然后将请求发送到当前实例上,比较常用的负载均衡策略有:轮询、随机、权重。
这里我选择对轮询和随机两个比较简单的来进行实现。
对于轮询,对于我们的网关项目,我们直接使用AtomicInteger进行累加计数即可。
然后我们从Nacos获取服务实例的数量之后,使用AtomicInteger中的数据和服务实例的数量进行取余运算或者进行与运算,我们就能得到需要负载均衡到的机器的路由了。
而随机则更加简单,我们得到服务实例数量之后,将随机数分为设定为小于等于这个数量即可。
思考清楚了两个负载均衡策略如何实现,我们得思考如何选择具体使用那个负载均衡策略,按照我们的规则,我们可以在规则中提供一个字段,这个字段用于选择具体使用的策略。
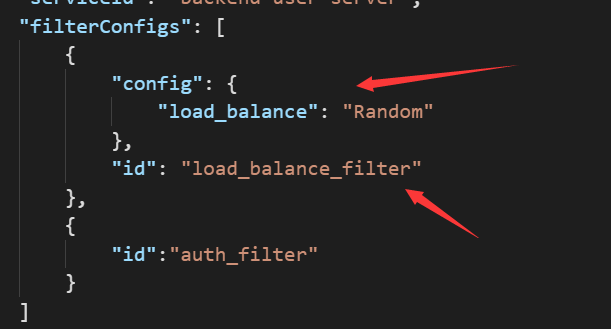
例如,按照上面的代码,我们解析完毕Rule之后,得到filterConfigs属性,并获取到其中的id和config配置,而这里的config配置就代表了负载均衡策略具体选择的是哪一个策略。
而具体的规则我们也在请求进入到网关并且被NettyCoreProcessor处理的时候进行过封装了。
```
// 根据请求对象里的uniqueId,获取资源服务信息(也就是服务定义信息)
ServiceDefinition serviceDefinition =
DynamicConfigManager.getInstance().getServiceDefinition(gateWayRequest.getUniqueId());
//根据请求对象获取规则
Rule rule = getRule(gateWayRequest, serviceDefinition.getServiceId());
// 构建我们而定GateWayContext对象
GatewayContext gatewayContext = new GatewayContext(serviceDefinition.getProtocol(), ctx,
HttpUtil.isKeepAlive(request), gateWayRequest, rule,0);
```
因此,我们可以直接从网关上下文中获取到当前请求对应的规则,然后从配置中心中拿出当前服务对应的规则。
查看代码比较容易理解,其实就是从网关上下文中获取到规则配置之后,拿出对应的config字段中的load_balance字段,这个字段就是我们选择的负载均衡的具体策略。
默认我们使用随机的负载均衡策略。
之后,我们对JSON进行解析并且得到具体选择的负载均衡策略即可。
```
public LoadBalanceGatewayRule getLoadBalanceRule(GatewayContext ctx) {
LoadBalanceGatewayRule loadBalanceRule = null;
Rule configRule = ctx.getRule();
if (configRule != null) {
Set filterConfigs = configRule.getFilterConfigs();
Iterator iterator = filterConfigs.iterator();
Rule.FilterConfig filterConfig;
while (iterator.hasNext()) {
filterConfig = (Rule.FilterConfig) iterator.next();
if (filterConfig == null) {
continue;
}
String filterId = filterConfig.getId();
if (filterId.equals(LOAD_BALANCE_FILTER_ID)) {
String config = filterConfig.getConfig();
String strategy = LOAD_BALANCE_STRATEGY_RANDOM;
if (StringUtils.isNotEmpty(config)) {
Map mapTypeMap = JSON.parseObject(config, Map.class);
strategy = mapTypeMap.getOrDefault(LOAD_BALANCE_KEY, strategy);
}
switch (strategy) {
case LOAD_BALANCE_STRATEGY_RANDOM:
loadBalanceRule = RandomLoadBalanceRule.getInstance(configRule.getServiceId());
break;
case LOAD_BALANCE_STRATEGY_ROUND_ROBIN:
loadBalanceRule = RoundRobinLoadBalanceRule.getInstance(configRule.getServiceId());
break;
default:
log.warn("No loadBalance strategy for service:{}", strategy);
loadBalanceRule = RandomLoadBalanceRule.getInstance(configRule.getServiceId());
break;
}
}
}
}
return loadBalanceRule;
}
```
**随机负载均衡过滤器实现:**
这里由于我们对于不同的服务会有不同的负载均衡的策略,但是这些策略在大多数时候是不会改变的,因此我们可以选择将其进行缓存,方法为使用一个HashMap即可。于是就有了如下代码:
```
package blossom.project.core.filter.loadbalance;
import blossom.project.common.config.DynamicConfigManager;
import blossom.project.common.config.ServiceInstance;
import blossom.project.common.exception.NotFoundException;
import blossom.project.core.context.GatewayContext;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ThreadLocalRandom;
import static blossom.project.common.enums.ResponseCode.SERVICE_INSTANCE_NOT_FOUND;
/**
* 当前类用于提供随机抽取后端服务的负载均衡实现
*/
@Slf4j
public class RandomLoadBalanceRule implements LoadBalanceGatewayRule {
private final String serviceId;
/**
* 服务列表
*/
private Set serviceInstanceSet;
public RandomLoadBalanceRule(String serviceId) {
this.serviceId = serviceId;
}
private static ConcurrentHashMap serviceMap = new ConcurrentHashMap<>();
public static RandomLoadBalanceRule getInstance(String serviceId) {
RandomLoadBalanceRule loadBalanceRule = serviceMap.get(serviceId);
if (loadBalanceRule == null) {
loadBalanceRule = new RandomLoadBalanceRule(serviceId);
serviceMap.put(serviceId, loadBalanceRule);
}
return loadBalanceRule;
}
@Override
public ServiceInstance choose(GatewayContext ctx,boolean gray) {
String serviceId = ctx.getUniqueId();
return choose(serviceId,gray);
}
@Override
public ServiceInstance choose(String serviceId,boolean gray) {
Set serviceInstanceSet =
DynamicConfigManager.getInstance().getServiceInstanceByUniqueId(serviceId,gray);
if (serviceInstanceSet.isEmpty()) {
log.warn("No instance available for:{}", serviceId);
throw new NotFoundException(SERVICE_INSTANCE_NOT_FOUND);
}
List instances = new ArrayList(serviceInstanceSet);
int index = ThreadLocalRandom.current().nextInt(instances.size());
ServiceInstance instance = (ServiceInstance) instances.get(index);
return instance;
}
}
```
**轮询负载均衡过滤器实现:**
同理,轮询的负载均衡过滤器的实现方式只不过变为了需要维护一个AtomicInteger用于计数。
```
@Slf4j
public class RoundRobinLoadBalanceRule implements LoadBalanceGatewayRule {
private AtomicInteger position = new AtomicInteger(1);
private final String serviceId;
public RoundRobinLoadBalanceRule(String serviceId) {
this.serviceId = serviceId;
}
private static ConcurrentHashMap serviceMap = new ConcurrentHashMap<>();
public static RoundRobinLoadBalanceRule getInstance(String serviceId) {
RoundRobinLoadBalanceRule loadBalanceRule = serviceMap.get(serviceId);
if (loadBalanceRule == null) {
loadBalanceRule = new RoundRobinLoadBalanceRule(serviceId);
serviceMap.put(serviceId, loadBalanceRule);
}
return loadBalanceRule;
}
@Override
public ServiceInstance choose(GatewayContext ctx,boolean gray) {
return choose(ctx.getUniqueId(),gray);
}
@Override
public ServiceInstance choose(String serviceId,boolean gray) {
Set serviceInstanceSet =
DynamicConfigManager.getInstance().getServiceInstanceByUniqueId(serviceId,gray);
if (serviceInstanceSet.isEmpty()) {
log.warn("No instance available for:{}", serviceId);
throw new NotFoundException(SERVICE_INSTANCE_NOT_FOUND);
}
List instances = new ArrayList(serviceInstanceSet);
if (instances.isEmpty()) {
log.warn("No instance available for service:{}", serviceId);
return null;
} else {
int pos = Math.abs(this.position.incrementAndGet());
return instances.get(pos % instances.size());
}
}
}
```
至此,我们的负载均衡过滤器就已经设计完毕了,如果有兴趣可以自己实现基于权重的负载均衡过滤器。
## 路由过滤器
在讲解具体的路由过滤器的实现之前,先来了解一下请求重试,因为我们的路由过滤器如果请求失败,一般会选择按照一定的次数进行重试。
### 请求重试
请求重试是指在请求失败之后再次尝试请求,一般情况下重试可以减少请求因为服务GC卡顿、网络丢包、网络阻塞等短暂问题而导致的失败;然而重试会增加请求总数量,不合理的重试策略甚至可能在服务端不稳定时,导致重试流量风暴,从而压垮服务端导致故障。
请求失败一般可以按照层级划分为连接失败和请求失败;而请求一般可分为幂等和非幂等请求。
连接失败:由于TCP握手失败,实际业务请求并未发送至服务端,所以对此类错误是可以安全的重试的,配合超时配置将链接超时设置在毫秒级别,可以有效的避免偶发网络拥塞、网络丢包等网络故障导致的报错,提升整体稳定性。
请求失败:由于网络连接已经完成,实际业务请求可能已经发送至服务端,服务端的业务逻辑可能已经执行过了;比如服务端超时,而实际服务端业务逻辑会继续执行完成。因此对于幂等请求相对安全,但是对于非幂等的请求,重试可能会有较大风险。
> 在短视频APP例子中,比如获取账户信息的请求就是幂等请求,不会有服务端数据的修改,重试操作是比较安全的;但是对于添加评论的请求,如果请求超时进行重试,就可能导致评论服务最终收到多个添加评论的请求,最终添加多个重复的评论,显然这是不正确的,会最终导致数据异常。
因此重试配置一般可归于以下几类
- **连接重试**: 因为连接重试风险低,收益高,一般情况下默认开启。
- **超时重试**: 需要判断业务接口是否幂等,如非幂等风险是否可控,来决定是否启用;提供重试退避策略:重试等待固定时长或逐次提升等待时长。
- **Backup Request**: 为减少服务的延迟波动。在设置时间内未返回,再次发送请求;例如使用P99作为阈值,来降低长尾问题。
同时为了防止大规模重试导致请求量总量成倍上升,最终压垮服务,重试一般需提供熔断错误率阈值,当请求错误率超过阈值时停止重试。
**实现思路:**
有了负载均衡过滤器的基础,讲解路由过滤器就会简单很多了。
路由过滤器其实要做的就是将我们在经过之前过滤器处理好的请求信息发送出去,去请求具体的后端服务实例。
因此我们要做的其实就是在过滤器方法中调用具体的执行路由的逻辑。
在这个部分中,我们的主要逻辑其实就是使用AsyncHttpClient发送异步请求,我们在之前已经成功的封装好了我们的请求信息,也就是这里的Request,之后我们我们使用AsyncHttpClient来执行这个异步请求,这个异步请求将会返回一个CompletableFuture对象,而我们知道CompletableFuture非常适合于异步任务的场景,这里我们基于CompletableFuture来实现当请求处理完毕之后的收尾工作。
这里我将花费一定的笔墨来介绍一下这里两个Completable调用的方法的区别。
主要区别在于**whenComplete**和**whenCompleteAsync**方法的使用。让我逐一分析这两种方法的不同之处:
1. **whenComplete方法**:
- **whenComplete**是一个非异步的完成方法。
- 当**CompletableFuture**的执行完成或者发生异常时,它提供了一个回调。
- 这个回调将在**CompletableFuture**执行的相同线程中执行。这意味着,如果**CompletableFuture**的操作是阻塞的,那么回调也会在同一个阻塞的线程中执行。
- 在这段代码中,如果**whenComplete**为**true**,则在**future**完成时使用**whenComplete**方法。这意味着**complete**方法将在**future**所在的线程中被调用。
2. **whenCompleteAsync方法**:
- **whenCompleteAsync**是异步的完成方法。
- 它也提供了一个在**CompletableFuture**执行完成或者发生异常时执行的回调。
- 与**whenComplete**不同,这个回调将在不同的线程中异步执行。通常情况下,它将在默认的**ForkJoinPool**中的某个线程上执行,除非提供了自定义的**Executor**。
- 在代码中,如果**whenComplete**为**false**,则使用**whenCompleteAsync**。这意味着**complete**方法将在不同的线程中异步执行。
- 特别注意哦,由于**ForkJoinPool中的线程是共用的**,ParallelStream中的线程也是用的ForkJoinPool,因此我推荐你手动设定这个线程池的大小,否则会出现一些异常哦。
好的,那我们接下来就可以看执行完毕请求之后,我们如何对请求的结果进行处理了。也就是我们的complete方法。
代码比较简单直接看注释就可以明白其中的意思,这里的代码涉及到了重试机制,重试的次数也是由配置中心的配置给出的,当我们的请求失败之后我们可以获取到,然后进行对应次数的重试。
并在请求的最后对请求信息进行日志记录。
**代码实现:**
```
@Override
public void doFilter(GatewayContext gatewayContext) throws Exception {
route(gatewayContext, hystrixConfig);
}
private CompletableFuture route(GatewayContext gatewayContext,
Optional hystrixConfig) {
Request request = gatewayContext.getRequest().build();
CompletableFuture future = AsyncHttpHelper.getInstance().executeRequest(request);
boolean whenComplete = ConfigLoader.getConfig().isWhenComplete();
if (whenComplete) {
future.whenComplete((response, throwable) -> {
complete(request, response, throwable, gatewayContext, hystrixConfig);
});
} else {
future.whenCompleteAsync((response, throwable) -> {
complete(request, response, throwable, gatewayContext, hystrixConfig);
});
}
return future;
}
public CompletableFuture executeRequest(Request request) {
ListenableFuture future = asyncHttpClient.executeRequest(request);
return future.toCompletableFuture();
}
private void complete(Request request, Response response, Throwable throwable, GatewayContext gatewayContext,
Optional hystrixConfig) {
//请求已经处理完毕 释放请求资源
gatewayContext.releaseRequest();
//获取网关上下文规则
Rule rule = gatewayContext.getRule();
//获取请求重试次数
int currentRetryTimes = gatewayContext.getCurrentRetryTimes();
int confRetryTimes = rule.getRetryConfig().getTimes();
//判断是否出现异常 如果是 进行重试
if ((throwable instanceof TimeoutException || throwable instanceof IOException) &&
currentRetryTimes <= confRetryTimes && !hystrixConfig.isPresent()) {
//请求重试
doRetry(gatewayContext, currentRetryTimes);
return;
}
try {
//之前出现了异常 执行异常返回逻辑
if (Objects.nonNull(throwable)) {
String url = request.getUrl();
if (throwable instanceof TimeoutException) {
log.warn("complete time out {}", url);
gatewayContext.setThrowable(new ResponseException(ResponseCode.REQUEST_TIMEOUT));
gatewayContext.setResponse(GatewayResponse.buildGatewayResponse(ResponseCode.REQUEST_TIMEOUT));
} else {
gatewayContext.setThrowable(new ConnectException(throwable, gatewayContext.getUniqueId(), url,
ResponseCode.HTTP_RESPONSE_ERROR));
gatewayContext.setResponse(GatewayResponse.buildGatewayResponse(ResponseCode.HTTP_RESPONSE_ERROR));
}
} else {
//没有出现异常直接正常返回
gatewayContext.setResponse(GatewayResponse.buildGatewayResponse(response));
}
} catch (Throwable t) {
gatewayContext.setThrowable(new ResponseException(ResponseCode.INTERNAL_ERROR));
gatewayContext.setResponse(GatewayResponse.buildGatewayResponse(ResponseCode.INTERNAL_ERROR));
log.error("complete error", t);
} finally {
gatewayContext.written();
ResponseHelper.writeResponse(gatewayContext);
//增加日志记录
accessLog.info("{} {} {} {} {} {} {}",
System.currentTimeMillis() - gatewayContext.getRequest().getBeginTime(),
gatewayContext.getRequest().getClientIp(),
gatewayContext.getRequest().getUniqueId(),
gatewayContext.getRequest().getMethod(),
gatewayContext.getRequest().getPath(),
gatewayContext.getResponse().getHttpResponseStatus().code(),
gatewayContext.getResponse().getFutureResponse().getResponseBodyAsBytes().length);
}
}
```
## 限流过滤器
服务限流是在高并发系统中,用于保护服务方的一种手段。通过限流功能,可以限制QPS的最大值、Connection的最大值,以避免被突发流量击溃,从而保障系统的高可用性。
业务场景:
- 突发流量保护
- 防止调用方高频误刷
> 在短视频APP的例子中,假如遇到突发热点新闻「xxx事件」,短视频流量突增,视频信息服务请求量成倍增加,导致CPU被打崩,服务崩溃,在突发流量消退前都将无法正常服务,所有用户都将受到影响;如果可以限制请求视频信息服务的请求总量,对无法支持的流量丢弃,使得部分用户能够正常使用APP,将损失降低,同时对服务进行扩容,进一步降低损失。
针对基础的使用场景,我们介绍以下2类限流:
- 单实例限流
- 分布式限流
在后续高阶章节我们还会介绍智能化的限流模式,通过程序自动识别是否限流。
### 单实例限流
单实例限流是为防止本实例的服务被打挂而进行的限流设置,单实例限流是为每个实例分配限流额度,确保单个实例接收到的QPS和Connection在设定阈值内,从而保障实例的稳定性。
一般对稳定性要求较高的服务都会先进行单实例压测,确定本服务单实例的Max QPS,然后利用本功能进行单实例QPS && Connection 的限制。
单实例限流对每个实例的阈值是一样的,所以当被调用服务的实例权重差别较大的时候,权重较高的实例因为流量更大,因此更容易触发限流阈值。
### 分布式限流
分布式限流则是通过SDK+中心存储令牌模式实现精准的集群限流模式。每个实例都会运行SDK限流逻辑(令牌桶限流算法),限流令牌将向中心存储(Redis / MySQL)申请令牌,从而实现精准的集群流量限制。
分布式限流优点:
- 能够精准的控制集群整体的MAX Qps,即使限流值小于实例数。
- 实例的权重并不影响触发限流的概率,所有实例共享令牌桶。
分布式限流缺点:
- 由于引入了SDK和中心存储,带来更大的运维成本。
- 请求前需要从中心存储申请令牌,带来一定性能开销。
常见的限流算法有令牌桶算法和漏桶算法,这里两种算法我们都可以考虑使用一下。
### 如何选择限流模式
这两种限流模式如何选择?
- 单实例限流:一般适用于保护服务自身不被打垮,例如计算型服务、缓存型服务、代理型服务等
- 分布式限流:一般适用于对集群整体限流精度有要求的服务,主要保护其依赖的第三方服务(数据库、缓存、中台服务等)。
限流是服务端将一视同仁的将无法承载的请求丢弃,在这种极端情况下,我们如何提高服务端的”性价比“,将有限的资源发挥最大的价值呢?嘿嘿,那这里卖个关子,留到服务降级的时候说。
首先,对于限流这一块,我们需要在配置中心配置限流规则。
例如限流的路径或者限流的服务。同时,根据你的服务是分布式服务还是单体服务,也需要考虑使用不同的方式来存储信息。
比如如果是分布式服务,就需要使用Redis,而如果是单体,那么考虑使用本地缓存即可,比如Guava或者Caffeine。
老样子,我们先编写一个接口,这个接口用于获取对应的限流过滤器。
```
public interface GatewayFlowControlRule {
/**
* 执行流控规则过滤器
* @param flowControlConfig
* @param serviceId
*/
void doFlowControlFilter(Rule.FlowControlConfig flowControlConfig, String serviceId);
}
```
按照上面的思路,我们将限流过滤器分为基于Redis和基于Guava两种方式实现的,一种为了分布式项目服务,一种为了单体项目服务。
代码比较好理解,不做过多的赘述。这里主要实现点在于实现基于Redis和基于Guava的计数器,比较简单,网络上教程比较多,篇幅有限,我就不贴出这一部分的具体代码了。
```
public class FlowControlByPathRule implements GatewayFlowControlRule {
private String serviceId;
private String path;
private RedisCountLimiter redisCountLimiter;
private static final String LIMIT_MESSAGE = "您的请求过于频繁,请稍后重试";
public FlowControlByPathRule(String serviceId, String path, RedisCountLimiter redisCountLimiter) {
this.serviceId = serviceId;
this.path = path;
this.redisCountLimiter = redisCountLimiter;
}
/**
* 存放路径-流控规则的map
*/
private static ConcurrentHashMap servicePathMap = new ConcurrentHashMap<>();
/**
* 通过服务id和路径获取具体的流控规则过滤器
*
* @param serviceId
* @param path
* @return
*/
public static FlowControlByPathRule getInstance(String serviceId, String path) {
StringBuffer buffer = new StringBuffer();
String key = buffer.append(serviceId).append(".").append(path).toString();
FlowControlByPathRule flowControlByPathRule = servicePathMap.get(key);
//当前服务不存在限流规则 则保存之
if (flowControlByPathRule == null) {
flowControlByPathRule = new FlowControlByPathRule(serviceId, path, new RedisCountLimiter(new JedisUtil()));
servicePathMap.put(key, flowControlByPathRule);
}
return flowControlByPathRule;
}
/**
* 根据路径执行流控
*
* @param flowControlConfig
* @param serviceId
*/
@Override
public void doFlowControlFilter(Rule.FlowControlConfig flowControlConfig, String serviceId) {
if (flowControlConfig == null || StringUtils.isEmpty(serviceId) || StringUtils.isEmpty(flowControlConfig.getConfig())) {
return;
}
//获得当前路径对应的流控次数
Map configMap = JSON.parseObject(flowControlConfig.getConfig(), Map.class);
//判断是否包含流控规则
if (!configMap.containsKey(FLOW_CTL_LIMIT_DURATION) || !configMap.containsKey(FLOW_CTL_LIMIT_PERMITS)) {
return;
}
//得到流控时间和时间内限制次数
double duration = configMap.get(FLOW_CTL_LIMIT_DURATION);
double permits = configMap.get(FLOW_CTL_LIMIT_PERMITS);
StringBuffer buffer = new StringBuffer();
//当前请求是否触发流控标志位
boolean flag = false;
String key = buffer.append(serviceId).append(".").append(path).toString();
//如果是分布式项目 那么我们就需要使用Redis来实现流控 单机则可以直接使用Guava
if (FLOW_CTL_MODEL_DISTRIBUTED.equalsIgnoreCase(flowControlConfig.getModel())) {
flag = redisCountLimiter.doFlowControl(key, (int) permits, (int) duration);
} else {
//单机版限流 直接用Guava
GuavaCountLimiter guavaCountLimiter = GuavaCountLimiter.getInstance(serviceId, flowControlConfig);
if (guavaCountLimiter == null) {
throw new RuntimeException("获取单机限流工具类为空");
}
double count = Math.ceil(permits / duration);
flag = guavaCountLimiter.acquire((int) count);
}
if (!flag) {
throw new RuntimeException(LIMIT_MESSAGE);
}
}
}
```
之后,我们的限流方法实现了之后,我们就可以将我们的请求通过这个限流方法去处理。
```
@Slf4j
@FilterAspect(id=FLOW_CTL_FILTER_ID,
name = FLOW_CTL_FILTER_NAME,
order = FLOW_CTL_FILTER_ORDER)
public class FlowControlFilter implements Filter {
@Override
public void doFilter(GatewayContext ctx) throws Exception {
Rule rule = ctx.getRule();
if(rule != null){
//获取流控规则
Set flowControlConfigs = rule.getFlowControlConfigs();
Iterator iterator = flowControlConfigs.iterator();
Rule.FlowControlConfig flowControlConfig;
while (iterator.hasNext()){
GatewayFlowControlRule flowControlRule = null;
flowControlConfig = (Rule.FlowControlConfig)iterator.next();
if(flowControlConfig == null){
continue;
}
String path = ctx.getRequest().getPath();
if(flowControlConfig.getType().equalsIgnoreCase(FLOW_CTL_TYPE_PATH)
&& path.equals(flowControlConfig.getValue())){
flowControlRule = FlowControlByPathRule.getInstance(rule.getServiceId(),path);
}else if(flowControlConfig.getType().equalsIgnoreCase(FLOW_CTL_TYPE_SERVICE)){
//TODO 可以自己实现基于服务的流控
}
if(flowControlRule != null){
//执行流量控制
flowControlRule.doFlowControlFilter(flowControlConfig,rule.getServiceId());
}
}
}
}
}
```
## 熔断与服务降级过滤器
服务降级是在服务所发出「实际请求需求」大于下游「稳定/可提供QPS」阈值时所使用的一种「服务维稳手段」,保障在部分极端情况下整体系统可以通过牺牲部分能力方式换来一定程度的可用性,而不是超出阈值后导致系统雪崩。
服务降级常见有两种方式,业务根据自身需求进行对应选择:
- 弃车保帅:按一定丢弃规则,仅丢弃部分请求,保障部分高优/核心 请求可以获得稳定服务。
- 贫富相均:对于所有请求一视同仁,按照相同比例丢弃。
对于基础系统/核心业务/关键服务,其组件可用性有着极高要求,如果因其承载资源需求过高而整体完全不可用,会导致大面积服务调用链直接断裂,并使故障进一步扩散,引起「系统雪崩」,其造成的巨大损失是我们不能接受的。
> 在短视频APP的例子中,如下图,假如因为突发事件流量,导致账户服务的流量增加触发了限流;但是对于短视频的场景下,视频播放功能价值显然高于评论功能的价值,在有限的资源情况下,账户服务如果主动将评论服务的流量进行降级,将资源腾挪给视频信息服务,舍弃评论功能,保护视频播放能力显然能获得更高性价比。
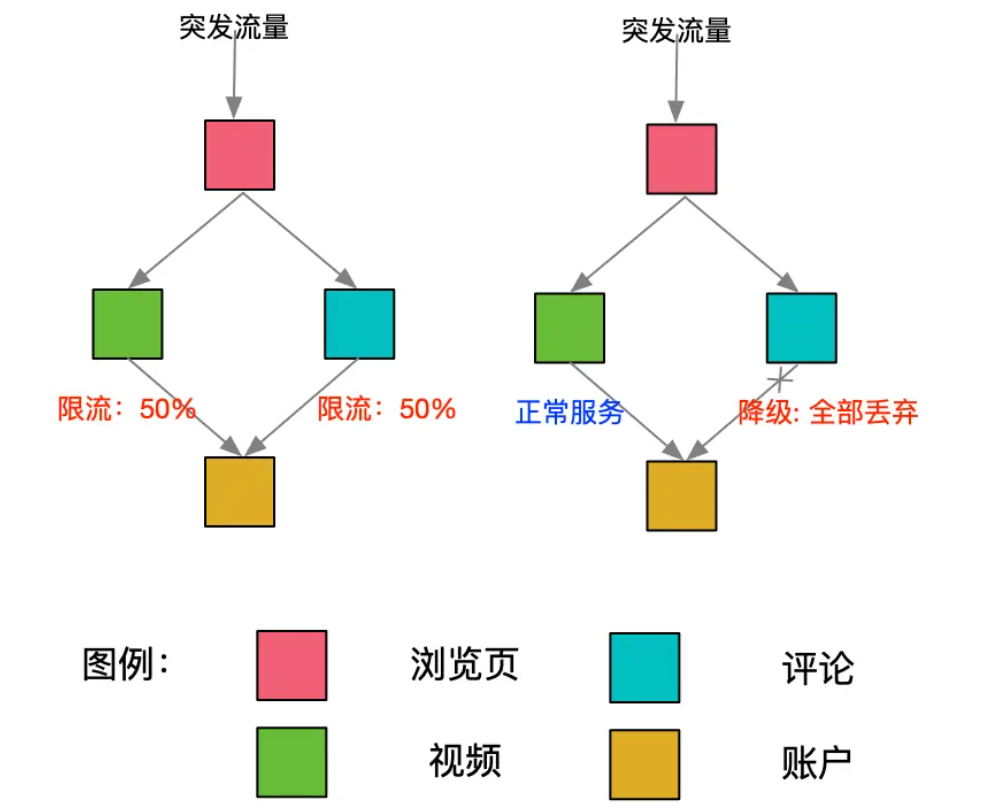
服务降级究其根本,即是“断臂求生”。对于实际业务场景而言,降级方式的评估即是对「付出成本」和「实际收获」的评估,可以从以下三个维度去抽象细化:
- 尽可能少丢弃—— “每一个请求都有价值”
- 尽可能丢弃价值较低的请求—— “请求与请求的价值是不同的”
- 尽可能丢弃性价比低的请求—— “吃了两份资源却只能产出一份价值的请求”
接下来我们开始实现熔断与服务降级。熔断与服务降级,在SpringCloud中设计到的就是我们的Hystrix,这里我们也将会考虑配合Hystrix来实现熔断与服务降级。如果不了解hystix的可以先进行一下了解。
首先引入Hystrix的依赖。
```
1.5.12
1.5.12
1.5.12
com.netflix.hystrix
hystrix-core
${hystrix.core.version}
com.netflix.hystrix
hystrix-metrics-event-stream
${hystrix.metrics.version}
com.netflix.hystrix
hystrix-javanica
${hystrix.javanica.version}
```
引入如上的依赖之后,我们就可以开始基于Hystrix编写如何进行熔断限流了。
我先贴出一套代码来大致介绍一下如何使用Hystrix实现熔断降级。
```
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixCommandKey;
import com.netflix.hystrix.HystrixCommandProperties;
import com.netflix.hystrix.HystrixThreadPoolProperties;
public class MyHystrixCommand extends HystrixCommand {
private final String fallbackValue;
protected MyHystrixCommand(String fallbackValue) {
super(Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("MyGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("MyCommand"))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(1000)) // 设置超时时间
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(10) // 设置线程池大小
);
this.fallbackValue = fallbackValue;
}
@Override
protected String run() throws Exception {
// 执行你的业务逻辑
return "Result of the actual operation";
}
@Override
protected String getFallback() {
// 执行降级逻辑
return fallbackValue;
}
}
```
上述代码中,我创建了一个自定义的 MyHystrixCommand 类,继承自 HystrixCommand 类。在该类的构造函数中,你可以配置Hystrix的一些属性,如组、命令名称、执行超时等。然后,你需要实现 run 方法来执行实际的业务逻辑,以及 getFallback 方法来执行降级逻辑。
接下来,你可以在应用中使用这个自定义的Hystrix命令:
```
String result = new MyHystrixCommand("Fallback Value").execute();
```
通过调用 execute 方法,你可以执行Hystrix命令,如果发生熔断,将会执行降级逻辑,返回降级值。
这种方式允许你更细粒度地控制熔断和降级的行为,但需要手动配置Hystrix的属性,如超时时间、线程池大小等。你可以根据具体需求进行定制。
所以,根据上面的情况,我们就已经大概知道了如何基于hystrix实现一套熔断降级的逻辑了。
那么接下来我们来编写具体的实现代码。
首先,我们需要在配置中心的配置中添加出来对hystrix的配置。
```
"hystrixConfigs":[{
"path":"/http-server/ping",
"timeoutInMilliseconds":5000,
"threadCoreSize":2,
"fallbackResponse":"熔断超时"
}]
```
之后,我们知道我们的具体执行逻辑是走过滤器的,所以我们需要在我们的路由过滤器这里添加额外的对Hystrix的配置,来监测我们最后转发请求的时候,如果这个请求处理失败或者超时时,要让他进行熔断降级的逻辑。
```
@Override
public void doFilter(GatewayContext gatewayContext) throws Exception {
//首先获取熔断降级的配置
Optional hystrixConfig = getHystrixConfig(gatewayContext);
//如果存在对应配置就走熔断降级的逻辑
if (hystrixConfig.isPresent()) {
routeWithHystrix(gatewayContext, hystrixConfig);
} else {
route(gatewayContext, hystrixConfig);
}
}
/**
* 获取hystrix的配置
*
* @param gatewayContext
* @return
*/
private static Optional getHystrixConfig(GatewayContext gatewayContext) {
Rule rule = gatewayContext.getRule();
Optional hystrixConfig =
rule.getHystrixConfigs().stream().filter(c -> StringUtils.equals(c.getPath(),
gatewayContext.getRequest().getPath())).findFirst();
return hystrixConfig;
}
```
可以看到,我上面的代码就是从配置中心中获取到Hystrix的配置,然后判断如果存在熔断降级的配置就走熔断降级的逻辑。
原先的没有熔断降级时候的route逻辑不用改变,我们需要额外创建一个方法,当存在熔断降级逻辑时走这个方法。
这里就按照我们上一节提到的代码的编写方式,进行代码的编写和配置即可。
```
/**
* 根据提供的GatewayContext和Hystrix配置,执行路由操作,并在熔断时执行降级逻辑。
* 熔断会发生在:
* 当 Hystrix 命令的执行时间超过配置的超时时间。
* 当 Hystrix 命令的执行出现异常或错误。
* 当连续请求失败率达到配置的阈值。
* @param gatewayContext
* @param hystrixConfig
*/
private void routeWithHystrix(GatewayContext gatewayContext, Optional hystrixConfig) {
HystrixCommand.Setter setter = //进行分组
HystrixCommand.Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey(gatewayContext.getUniqueId()))
.andCommandKey(HystrixCommandKey.Factory.asKey(gatewayContext.getRequest().getPath()))
//线程池大小设置
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(hystrixConfig.get().getThreadCoreSize()))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
//线程池
.withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.THREAD)
//超时时间
.withExecutionTimeoutInMilliseconds(hystrixConfig.get().getTimeoutInMilliseconds())
.withExecutionIsolationThreadInterruptOnTimeout(true)
.withExecutionTimeoutEnabled(true));
// 创建一个新的HystrixCommand对象,用于执行实际的路由操作。
new HystrixCommand