diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/LICENSE b/PyTorch/contrib/cv/semantic_segmentation/DPT/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..17e19b8d4874a7c5b1541ccaa4e217cb312d2d65
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/LICENSE
@@ -0,0 +1,203 @@
+Copyright (c) OpenMMLab. All rights reserved
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2021 Huawei Technologies Co., Ltd
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/README.md b/PyTorch/contrib/cv/semantic_segmentation/DPT/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fda23c2ec773a23373c15d3439cd6bbb023a8c07
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/README.md
@@ -0,0 +1,200 @@
+# DPT for PyTorch
+
+- [概述](概述.md)
+- [准备训练环境](准备训练环境.md)
+- [开始训练](开始训练.md)
+- [训练结果展示](训练结果展示.md)
+- [版本说明](版本说明.md)
+
+
+
+# 概述
+
+## 简述
+
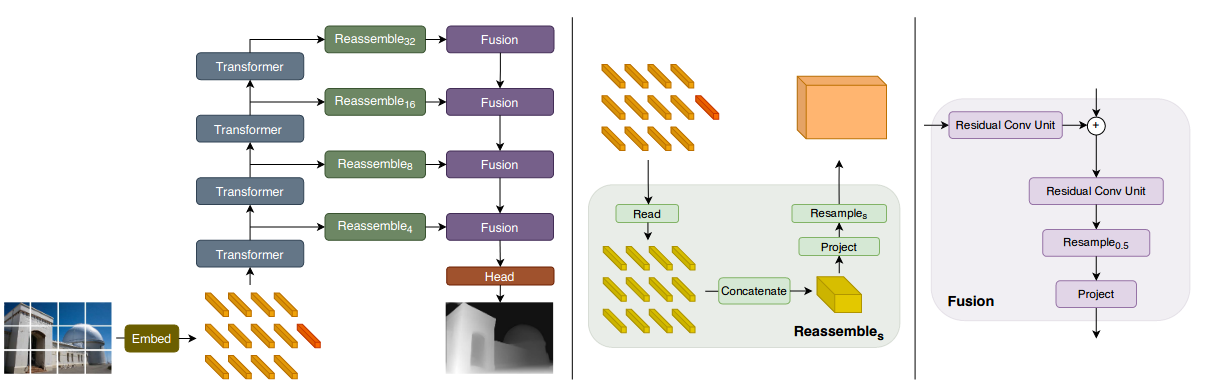
+DPT是一种密集的预测体系结构,它基于编码器-解码器的设计,利用transformer作为编码器的基本计算构建块。使用 ViT 作为 encoder 结构,把原图切分为不重叠的 token,然后使用 MHSA 获得这些经过编码的 token 之间的 attention。transformer 处理后,token 的数量是不变的,且它们之间的 attention 是一对一的,每个 token 都可以获得和其他 token 的关系,能够获得全局感受野下的特征,空间分辨率也不会改变。
+
+
+- 参考实现:
+
+ ```
+ url=https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dpt
+ ```
+
+- 适配昇腾 AI 处理器的实现:
+
+ ```
+ url=https://gitee.com/ascend/ModelZoo-PyTorch.git
+ code_path=PyTorch/contrib/cv/classification
+ ```
+
+- 通过Git获取代码方法如下:
+
+ ```
+ git clone {https://github.com/open-mmlab/mmsegmentation} # 克隆仓库的代码
+ cd {mmsegmentation} # 切换到/mmsegmentaion目录下
+ ```
+
+- 通过单击“[立即下载](https://github.com/open-mmlab/mmsegmentation/archive/refs/heads/master.zip)”,下载源码包。
+
+# 准备训练环境
+
+## 准备环境
+
+- 当前模型支持的固件与驱动、 CANN 以及 PyTorch 如下表所示。
+
+ **表 1** 版本配套表
+
+ | 配套 | 版本 |
+ | ---------- | ------------------------------------------------------------ |
+ | 固件与驱动 | [1.0.15](https://www.hiascend.com/hardware/firmware-drivers?tag=commercial) |
+ | CANN | [5.1.RC1](https://www.hiascend.com/software/cann/commercial?version=5.1.RC1) |
+ | PyTorch | [1.5.0](https://gitee.com/ascend/pytorch/tree/v1.5.0/) |
+
+- 环境准备指导。
+
+ 请参考《[Pytorch框架训练环境准备](https://www.hiascend.com/document/detail/zh/ModelZoo/pytorchframework/ptes)》。
+
+- 安装依赖(根据模型需求,按需添加所需依赖)。
+
+ ```
+ pip install -r requirements.txt
+ ```
+ 构建mmcv.
+ ```
+ # 克隆mmcv仓库代码
+ git clone -b v1.4.4 https://github.com/open-mmlab/mmcv.git
+
+ # configure
+ cd /mmcv
+
+ # copy
+ rm -rf ./mmcv
+ mkdir mmcv
+ cp -r mmcv_replace/* ./mmcv/
+
+ # compile
+ MMCV_WITH_OPS=1 pip install -e . -v
+
+ cd /${模型文件夹名称}
+ ```
+ 构建mmsegmentation.
+ 用本页configs/下文件替换mmsegmentation/configs同名文件,mmseg/下文件替换/mmsegmentation/mmseg/下的的同名文件, ./tools/下文件替换/mmsegmentation/tools下同名文件
+ ```
+ # 克隆仓库的代码
+ git clone https://github.com/open-mmlab/mmsegmentation
+
+ # configure
+ cd /mmsegmentation
+
+ # copy
+ cp -r /${你的存放路径}/configs/* ./configs/
+ cp -r /${你的存放路径}/mmseg/* ./mmseg/
+ cp -r /${你的存放路径}/tools/* ./tools/
+
+ # compile
+ pip install -e . -v
+ ```
+
+## 准备数据集
+
+1. 获取数据集。
+
+ 用户自行获取原始数据集,可选用的开源数据集为[ade20k](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip),将数据集上传到服务器任意路径下并解压。
+
+ 数据集目录结构如下所示:
+ ```
+ ├──ADE20K/
+ | |──annotations/
+ | | |──training/
+ | | | ADE_train_00000001.png
+ | | | ADE_train_00000002.png
+ | | | ...
+ | | |──validation/
+ | | | ADE_val_00000001.png
+ | | | ADE_val_00000002.png
+ | | | ...
+ | |──images/
+ | | |──training/
+ | | | ADE_train_00000001.jpg
+ | | | ADE_train_00000002.jpg
+ | | | ...
+ | | |──validation/
+ | | | ADE_val_00000001.jpg
+ | | | ADE_val_00000002.jpg
+ | | | ...
+ | |──objectInfo150.txt
+ | |──sceneCategories.txt
+ ```
+
+## 获取预训练模型
+
+请参考原始仓库上的README.md进行预训练模型获取或[点击这里](https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_224-80ecf9dd.pth)。将获取的预训练模型放至在根目录下/pretrain,接着对模型进行转换
+```
+python mmsegmentation/tools/model_converters/vit2mmseg.py pretrain/jx_vit_base_p16_224-80ecf9dd.pth pretrain/vit_base_p16_224-80ecf9dd.pth
+```
+
+## 修改
+- torch.nn.parallel._function._get_stream中使用了torch.cuda,修改为torch.npu
+
+# 开始训练
+
+## 训练模型
+
+1. 进入根目录。
+
+ ```
+ cd .
+ ```
+
+2. 运行训练脚本。
+
+ 该模型支持单机单卡训练和单机8卡训练。
+
+ - 单机单卡训练
+
+ 启动单卡训练。
+
+ ```
+ # training 1p accuracy
+ bash ./test/train_full_1p.sh --data_path=xxx
+ # training 1p performance
+ bash ./test/train_performance_1p.sh --data_path=xxx
+ ```
+
+ - 单机8卡训练
+
+ 启动8卡训练。
+
+ ```
+ # training 8p accuracy
+ bash ./test/train_full_8p.sh --data_path=xxx
+ # training 8p performance
+ bash ./test/train_performance_8p.sh --data_path=xxx
+ ```
+
+ 训练完成后,权重文件默认保存在/work_dir下,并输出模型训练精度和性能信息。
+
+# 训练结果展示
+
+**表 2** 训练结果展示表
+
+| NAME | decode.acc_seg | FPS | iters | AMP_Type |
+| ------- | ----- | ---: | ------ | -------: |
+| 1p-GPU | | 5.98 | 500 | O1,None |
+| 1p-NPU | | 0.09 | 500 | O1,None |
+| 8p-GPU | 80.2740 | 37.20| 7500 | O1,None |
+| 8p-NPU | 81.0251 | 0.57 | 7500 | O1,None |
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/datasets/ade20k.py b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/datasets/ade20k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9e9cfa42ad297475d230525b585678a72183174
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/datasets/ade20k.py
@@ -0,0 +1,69 @@
+# encoding=utf-8
+# Copyright 2021 Huawei Technologies Co., Ltd
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# dataset settings
+dataset_type = 'ADE20KDataset'
+data_root = '/home/savepath/yuhaiyan/mmsegmentation/data/ad20k/ADEChallengeData2016' #'data/ade/ADEChallengeData2016'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+crop_size = (512, 512)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', reduce_zero_label=True),
+ dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
+ dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PhotoMetricDistortion'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 512),
+ # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ train=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/training',
+ ann_dir='annotations/training',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ data_root=data_root,
+ img_dir='images/validation',
+ ann_dir='annotations/validation',
+ pipeline=test_pipeline))
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/default_runtime.py b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/default_runtime.py
new file mode 100644
index 0000000000000000000000000000000000000000..48926a1de92f76ce685d0c9726cc12b46c220d17
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/default_runtime.py
@@ -0,0 +1,30 @@
+# encoding=utf-8
+# Copyright 2021 Huawei Technologies Co., Ltd
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False),
+ # dict(type='TensorboardLoggerHook')
+ # dict(type='PaviLoggerHook') # for internal services
+ ])
+# yapf:enable
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+cudnn_benchmark = True
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/models/dpt_vit-b16.py b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/models/dpt_vit-b16.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d10c3ee4a637e0f112e9fae9ddf969d1afbd2a2
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/models/dpt_vit-b16.py
@@ -0,0 +1,45 @@
+# encoding=utf-8
+# Copyright 2021 Huawei Technologies Co., Ltd
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+norm_cfg = dict(type='SyncBN', requires_grad=True)
+model = dict(
+ type='EncoderDecoder',
+ pretrained='pretrain/vit-b16_p16_224-80ecf9dd.pth', # noqa
+ backbone=dict(
+ type='VisionTransformer',
+ img_size=224,
+ embed_dims=768,
+ num_layers=12,
+ num_heads=12,
+ out_indices=(2, 5, 8, 11),
+ final_norm=False,
+ with_cls_token=True,
+ output_cls_token=True),
+ decode_head=dict(
+ type='DPTHead',
+ in_channels=(768, 768, 768, 768),
+ channels=256,
+ embed_dims=768,
+ post_process_channels=[96, 192, 384, 768],
+ num_classes=150,
+ readout_type='project',
+ input_transform='multiple_select',
+ in_index=(0, 1, 2, 3),
+ norm_cfg=norm_cfg,
+ loss_decode=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
+ auxiliary_head=None,
+ # model training and testing settings
+ train_cfg=dict(),
+ test_cfg=dict(mode='whole')) # yapf: disable
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/schedules/schedule_160k.py b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/schedules/schedule_160k.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b35ca427b8c14ee8973ed6c56f0a1e822a5b008
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/_base_/schedules/schedule_160k.py
@@ -0,0 +1,24 @@
+# encoding=utf-8
+# Copyright 2021 Huawei Technologies Co., Ltd
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# optimizer
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
+optimizer_config = dict()
+# learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
+# runtime settings
+runner = dict(type='IterBasedRunner', max_iters=160000)
+checkpoint_config = dict(by_epoch=False, interval=16000)
+evaluation = dict(interval=16000, metric='mIoU', pre_eval=True)
diff --git a/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/dpt/README.md b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/dpt/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e6257711fc6979a9d8bb50c0577784842b1a8a0
--- /dev/null
+++ b/PyTorch/contrib/cv/semantic_segmentation/DPT/configs/dpt/README.md
@@ -0,0 +1,67 @@
+# DPT
+
+[Vision Transformer for Dense Prediction](https://arxiv.org/abs/2103.13413)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at [this https URL](https://github.com/isl-org/DPT).
+
+
+
+
+
+